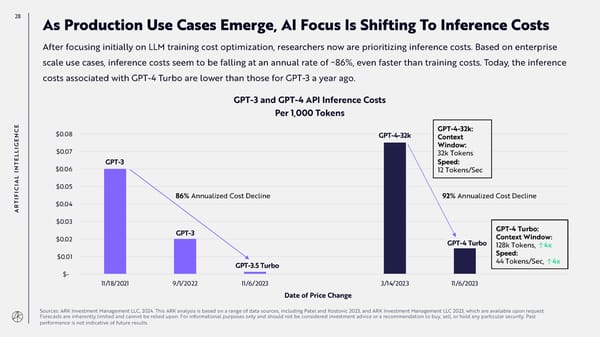
28 As Production Use Cases Emerge, AI Focus Is Shifting To Inference Costs After focusing initially on LLM training cost optimization, researchers now are prioritizing inference costs. Based on enterprise scale use cases, inference costs seem to be falling at an annual rate of ~86%, even faster than training costs. Today, the inference costs associated with GPT-4 Turbo are lower than those for GPT-3 a year ago. GPT-3 and GPT-4 API Inference Costs Per 1,000 Tokens E GPT-4-32k: C $0.08 N GPT-4-32k Context E G Window: I L $0.07 32k Tokens L E GPT-3 Speed: T N $0.06 12 Tokens/Sec I AL I $0.05 C I F 86% Annualized Cost Decline 92% Annualized Cost Decline I T $0.04 AR $0.03 GPT-3 GPT-4 Turbo: $0.02 GPT-4 Turbo Context Window: 128k Tokens, ↑4x $0.01 Speed: GPT-3.5 Turbo 44 Tokens/Sec, ↑4x $- 11/18/2021 9/1/2022 11/6/2023 3/14/2023 11/6/2023 Date of Price Change Sources: ARK Investment Management LLC, 2024. This ARK analysis is based on a range of data sources, including Patel and Kostovic 2023, and ARK Investment Management LLC 2023, which are available upon request. Forecasts are inherently limited and cannot be relied upon. For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security. Past performance is not indicative of future results.
 Annual Research Report | Big Ideas 2024 Page 27 Page 29
Annual Research Report | Big Ideas 2024 Page 27 Page 29