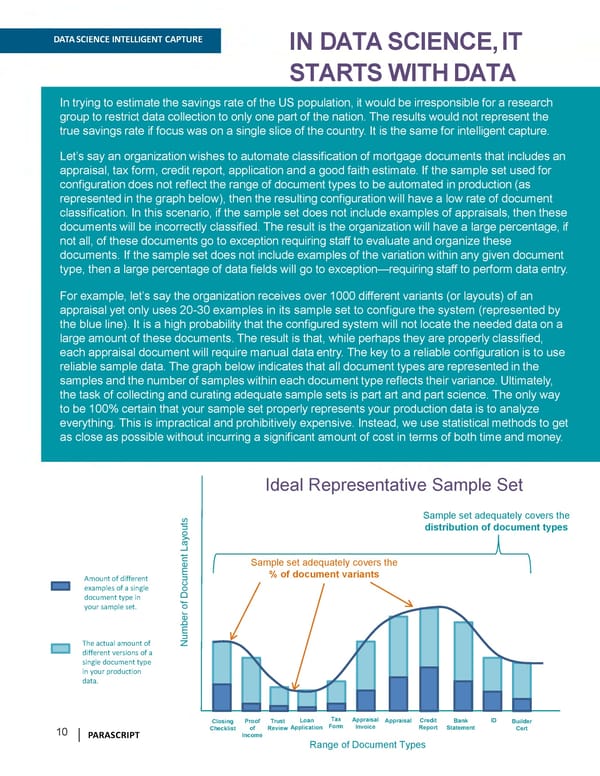
DATA SCIENCE INTELLIGENT CAPTURE IN DATA SCIENCE,IT STARTS WITHDATA In trying to estimate the savings rate of the US population, it would be irresponsible for a research group to restrict data collection to only one part of the nation. The results would not represent the true savings rate if focus was on a single slice of the country. It is the same for intelligent capture. Let’s say an organization wishes to automate classification of mortgage documents that includes an appraisal, tax form, credit report, application and a good faith estimate. If the sample set used for configuration does not reflect the range of document types to be automated in production (as represented in the graph below), then the resulting configuration will have a low rate of document classification. In this scenario, if the sample set does not include examples of appraisals, then these documents will be incorrectly classified. The result is the organization will have a large percentage, if not all, of these documents go to exception requiring staff to evaluate and organize these documents. If thesampleset doesnot includeexamplesofthevariation withinany given document type, thena large percentage of data fields will go to exception—requiring staff to perform data entry. For example, let’s say the organization receives over 1000 different variants (or layouts) of an appraisal yet only uses 20-30 examples in its sample set to configure the system (represented by the blue line). It is a high probability that the configured system will not locate the needed data on a large amount of these documents. The result is that, while perhaps they are properly classified, each appraisal document will require manual dataentry. The key to a reliable configuration is to use reliable sample data. The graph below indicates that all document typesare representedin the samplesandthenumberofsampleswithineachdocumenttypereflectstheirvariance. Ultimately, the task of collecting and curating adequate sample sets is part art and part science. The only way to be 100%certain that your sample set properly represents your production data is to analyze everything. This is impractical and prohibitively expensive. Instead, we use statistical methods to get as close as possible without incurring a significant amount of cost in terms of both time and money. Ideal Representative Sample Set Sample set adequately covers the ts distribution of document types ou y La t en Sample set adequately covers the Amount of different % of document variants um examples of a single document type in Doc your sample set. of r be The actual amount of Num different versions of a single document type in your production data. Tax Appraisal Closing Proof Trust Loan Appraisal Credit Bank ID Builder Form Invoice Checklist of Review Application Report Statement Cert 10 PARASCRIPT Income Range of Document Types
 Data Science with Intelligent Capture Page 9 Page 11
Data Science with Intelligent Capture Page 9 Page 11