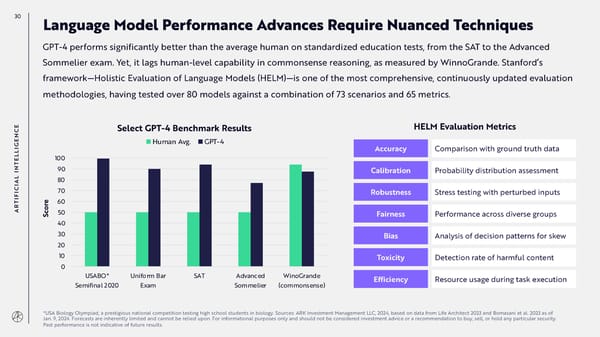
30 Language Model Performance Advances Require Nuanced Techniques GPT-4 performs significantly better than the average human on standardized education tests, from the SAT to the Advanced Sommelier exam. Yet, it lags human-level capability in commonsense reasoning, as measured by WinnoGrande. Stanford’s framework—Holistic Evaluation of Language Models (HELM)—is one of the most comprehensive, continuously updated evaluation methodologies, having tested over 80 models against a combination of 73 scenarios and 65 metrics. E Select GPT-4 Benchmark Results HELM Evaluation Metrics C N E Human Avg. GPT-4 G I Accuracy Comparison with ground truth data L L 100 E T N 90 I Calibration Probability distribution assessment AL 80 I C 70 I Robustness Stress testing with perturbed inputs F I e T r 60 AR co 50 Fairness Performance across diverse groups S 40 30 Bias Analysis of decision patterns for skew 20 10 Toxicity Detection rate of harmful content 0 USABO* Uniform Bar SAT Advanced WinoGrande Efficiency Resource usage during task execution Semifinal 2020 Exam Sommelier (commonsense) *USA Biology Olympiad, a prestigious national competition testing high school students in biology. Sources: ARK Investment Management LLC, 2024, based on data from Life Architect 2023 and Bomasani et al. 2023 as of Jan. 9, 2024. Forecasts are inherently limited and cannot be relied upon. For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security. Past performance is not indicative of future results.
 Annual Research Report | Big Ideas 2024 Page 29 Page 31
Annual Research Report | Big Ideas 2024 Page 29 Page 31