Startup Tools: Web Application Frameworks

 By On December 18, 2012
By On December 18, 2012
 When it comes to technology, it can be confusing out there for the business-minded (read: non-technical) co-founder.
When it comes to technology, it can be confusing out there for the business-minded (read: non-technical) co-founder.
Do those snowboard-loving, flip-flop wearing, EDM-listening, tattoo-having jackanapes-for-developers ridicule you with their fancy words and assault you with offensive acronyms? Do you think that JSON was that guy with the hockey mask and chainsaw in "Friday the 13th"? Thought Ruby was a reference to Grandma's dear friend at the nursing home?
Take heart, my friend, there is still hope. I am the co-founder and CTO of a startup called Speek, and I am here to help. Here is a quick guide to some of the popular technologies that today's startups use to change the world.
1. Node.jsNode.js is a platform built on Chrome's JavaScript runtime designed to easily build fast, scalable network applications. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient, perfect for data-intensive real-time applications that run across distributed devices.
Translation: Node.js makes it much easier, faster and efficient for your development team to do cool shit in your app in real-time that will melt your users' faces.
Why should you care?Historically, it was fairly time-intensive and very resource-intensive to crunch data or logic or to otherwise do stuff in real time within your app. Developers had to either use a request/response pattern via web services, or use crazy AJAX-based black magic. Web services are asynchronous by nature, so this was problematic. AJAX could make things appear to be happening more real-time, but took a toll on server and/or client resources that made it harder to scale efficiently.
Node.js allows developers to do things in real-time more easily, in way that scales pretty damn well.
What's it good for?
- Chat apps
- Synchronous drawing or note-taking features
- Collaboration or communication apps
- Snazzy search and search results manipulation
- Anything that requires stuff to happen in a synchronous or real-time manner
Pretty much everyone is using Node in some way, shape or form these days. So many companies are using node in some way, shape, or form today that it would be easier to list those not using it. Some notable users are:
2. Ruby on RailsRuby on Rails is an open-source web framework optimized for programmer happiness and sustainable productivity. It lets you write beautiful code by favoring convention over configuration. Ruby on Rails was invented by 37 Signals - the same folks that make Basecamp, Highrise, Campfire and some other cool products.
Translation: Ruby on Rails lets your developers build cool shit really, really quickly. It will also help you recruit developers because they love Ruby on Rails.
Why should you care?Ruby on Rails should shorten your development cycles to build products and features. Added bonus: It will let you "fail fast" with concepts and features, because it makes it very easy to throw prototypes and tests together.
What's it good for?Ruby on Rails should be your main programming language for your Web app.
Who's using it? 3. NoSQLIn short, NoSQL database management systems are useful when working with a huge quantity of data when a relational model isn't required. The data can be structured, but NoSQL is most useful when what really matters is the ability to store and retrieve great quantities of data, not the relationships between elements.
Translation: NoSQL databases are great for storing mass amounts of data in a really dumb way.
Why should you care?Web and mobile products are starting to be expected to do more in real-time or at least very quickly. User expectations are very high. NoSQL, combined with Node, will save you a ton of development time.
What's it good for?Your typical relational databases like MySQL, SQL Server and Oracle are great for storing highly-structured and relational data but are not ideal great at storing up simple data very quickly so that the logic or interface layer of your app can manipulate it. NoSQL saves the day.
Where can I find it? Some popular NoSQL databases are:
Who's using it? Pretty much everyone is using NoSQL databases these days, but to name a few:
4. GithubGithub is a cloud-based implementation of the Git source code repository system. Git is a free and open source distributed version control system designed to handle a wide array of projects with speed and efficiency.
Translation: Github gives the source code behind your app a place to live. Since it's hosted, no setup or maintenance is needed. It also comes with some additional bells and whistles that make automating builds and deployments faster and easier, and is very conducive to distributed development teams. Lastly, developers love Github.
Why should you care?The days of having your entire development team sitting in the same room together are gone for most startups. Github makes it easier for distributed development teams to avoid source code messes. Further, since Github is a SaaS, you avoid spending precious time on keeping the source code management system up and running.
What's it good for?
- Distributed and non-distributed development teams
- Any kind of source code management
- Continuous deployment and integration environments
- Any Web or mobile development efforts
In 2006, Amazon Web Services (AWS) began offering IT infrastructure services to businesses in the form of web services- - now commonly known as cloud computing. One of the key benefits of cloud computing is the opportunity to replace up-front capital infrastructure expenses with low variable costs that scale with your business. EC2 stands for Elastic Cloud Compute and is one of several offerings that make up AWS.
Translation: AWS allows you to host your Web apps in a highly scalable way yet only paying for the resources you actually use. It also allows your tech team to help themselves in real time when they need to add servers.
Why should you care?AWS tends to be cheaper and faster than traditional hosting. It is also "elastic" in nature. This means that you can set up your AWS "servers" to spin up and spin down based on traffic and load so you can theoretically handle infinite load. AWS also saves you from being blocked, waiting for some low-level network engineer at your hosting company to plug a cord in. AWS has a full-blown API and admin panel that allows your techies to help themselves and change things instantly.
What's it good for?AWS is great for variable load or traffic. It's also good for sites that get have seasonal spikes. AWS will not save you any real money in the very early days, in terms of hosting. Nor will it likely AWS will likely not make financial sense when you hit super-high constant load. However, AWS is great fromor when you first start growing to when you've officially made it.
Who's using it?AWS is another one being used by that is pretty much being used by everyone these days, including my company Speek, as well as:
Here are some of the more popular examples:
6. JSONJSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write., and It is easy for machines to parse and generate. It is based on a subset of the JavaScript pProgramming lLanguage. JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language.
Translation: You've heard of SOAP and REST right? JSON plays nicely with REST is newer and better than traditional XML. It also plays very nicely with the fancy new UI interactivity that is all the rage these days.
Why should you care?All of that whiz-bang interactive stuff you want your web or mobile product do will be done faster, easier, better with JSON.
What's it good for?JSON is great for exchanging or retrieving data that needs to be manipulated, massaged, mashed up or otherwise tweaked.
Who's using it?EVERYONE.
7. Continuous Integration (CI) and Continuous Deployment (CD)In software engineering, continuous integration (CI) is the practice of merging all developer code with a shared mainline/trunk several times a day. Its main aim is to prevent integration problems.
CI intended to be used in combination with automated unit tests written through the practices of tTest- driven development. Initially, meant this was conceived of as running and verifying all unit tests and verifying they all passed before committing to the mainline. Later elaborations of the concept introduced build servers, which automatically run the unit tests periodically - or even after every commit- and report the results to the developers.
Continuous Deployment is a process by which software is released several times throughout the day - in minutes versus days, weeks, or months.
Translation: When more than one developer is writing code, it makes itis hell to merge everyone's code together and ensure shit didn't break. Continuous Integration is an automated process that ensures integration hell doesn't occur. Continuous Deployment takes CI one-step further and even by automatinges deploymenting stuff to live servers in small chunks so that you avoid the risks of big bang releases that can also break shit.
Why should you care?Continuous Integration and Continuous Deployment will allow your development team to get more stuff done, break less stuff and push to production very frequently. Also, since CI and CD typically require a suite of unit tests, they indirectly help you save time on regression testing.
What's it good for?Everything everywhere.
Who's using it?Everyone everywhere who builds software that doesn't suck.
8. WebRTCWebRTC is a free, open project that enables web browsers with Real-Time Communications (RTC) capabilities via simple Javascript APIs. The WebRTC components have been optimized to best serve this purpose.
Translation: You know how bad it sucks to try and do real-time audio or video in a web browser using flash? WebRTC makes it so that you no longer need to use flash. You can now do things like VoIP and Video Chat natively inside the browser.
Why should you care?WebRTC is HOT right now and is moving very quickly. It is already supported in Opera browsers and in Chrome 23. Firefox will likely fully support it next, with Safari to follow. IE may or may not ever support it, but who cares about them, anyway?.
There are major players backing WebRTC like Google. Also, major players in the telephony space have already released WebRTC clients - like Twilio.
WebRTC is going to be a total game changer.
What's it good for?WebRTC will be good for a real-time communications in a web or mobile browser. It will be specifically good for real-time audio and video communication using nothing more than a browser (no downloads or installs required).
Who's using it?[Original image courtesy CircaSassy]

This article has multiple issues. Please help improve it or discuss these issues on the talk page.
A web application framework ( WAF) is a software framework that is designed to support the development of dynamic websites, web applications, web services and web resources. The framework aims to alleviate the overhead associated with common activities performed in web development. For example, many frameworks provide libraries for database access, templating frameworks and session management, and they often promote code reuse. For a comparison of concrete web application frameworks, see Comparison of web application frameworks.
This article Please help to lacks historical information on the subject. Specifically: sources and the dates some of the ideas arose should be added. add historical material to help counter systemic bias towards recent information. (June 2013)
As the design of the World Wide Web was not inherently dynamic, early hypertext consisted of hand-coded HTML that was published on web servers. Any modifications to published pages needed to be performed by the pages' author. To provide a dynamic web page that reflected user inputs, the Common Gateway Interface (CGI) standard was introduced for interfacing external applications with web servers. CGI could adversely affect server load, though, since each request had to start a separate process.
Programmers wanted tighter integration with the web server to enable high-traffic web applications. The Apache HTTP Server, for example, supports modules that can extend the web server with arbitrary code executions (such as mod perl) or forward specific requests to a web server that can handle dynamic content (such as mod jk). Some web servers (such as Apache Tomcat) were specifically designed to handle dynamic content by executing code written in some languages, such as Java.
Around the same time, full integrated server/language development environments first emerged, such as WebBase and new languages specifically for use in the web started to emerge, such as ColdFusion, PHP and Active Server Pages.
While the vast majority of languages available to programmers to use in creating dynamic web pages have libraries to help with common tasks, web applications often require specific libraries that are useful in web applications, such as creating HTML (for example, JavaServer Faces). Eventually, mature, "full stack" frameworks appeared, that often gathered multiple libraries useful for web development into a single cohesive software stack for web developers to use. Examples of this include ASP.NET, JavaEE (Servlets), WebObjects, web2py, OpenACS, Catalyst, Mojolicious, Ruby on Rails, Django, Zend Framework, Yii, CakePHP and Symfony.
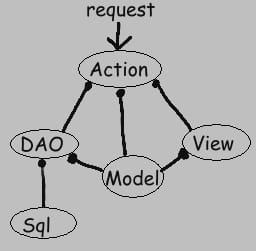
Most web application frameworks are based on the model-view-controller (MVC) pattern.
Many frameworks follow the MVC architectural pattern to separate the data model with business rules from the user interface. This is generally considered a good practice as it modularizes code, promotes code reuse, and allows multiple interfaces to be applied. In web applications, this permits different views to be presented, such as web pages for humans, and web service interfaces for remote applications.
Push-based vs. pull-based
Most MVC frameworks follow a push-based architecture also called "action-based". These frameworks use actions that do the required processing, and then "push" the data to the view layer to render the results. Struts, Django, Ruby on Rails, Symfony, Yii, Spring MVC, Stripes, Play, CodeIgniter are good examples of this architecture. An alternative to this is pull-based architecture, sometimes also called "component-based". These frameworks start with the view layer, which can then "pull" results from multiple controllers as needed. In this architecture, multiple controllers can be involved with a single view. Struts2, Lift, Tapestry, JBoss Seam, JavaServer Faces, and Wicket are examples of pull-based architectures.
In three-tier organization, applications are structured around three physical tiers: client, application, and database. The database is normally an RDBMS. The application contains the business logic, running on a server and communicates with the client using HTTP. The client, on web applications is a web browser that runs HTML generated by the application layer. The term should not be confused with MVC, where, unlike in three-tier architecture, it is considered a good practice to keep business logic away from the controller, the "middle layer".
Frameworks are built to support the construction of internet applications based on a single programming language, ranging in focus from general purpose tools such as Zend Framework and Ruby on Rails, which augment the capabilities of a specific language, to native-language programmable packages built around a specific user application, such as Content Management systems, some mobile development tools and some portal tools.
For example, Zend Framework.
For example, WikiBase/ WikiWikiWeb.
For example, JBoss Portal.
In web application frameworks, content management is the way of organizing, categorizing, and structuring the information resources like text, images, documents, audio and video files so that they can be stored, published, and edited with ease and flexibility. A content management system (CMS) is used to collect, manage, and publish content, storing it either as components or whole documents, while maintaining dynamic links between components.
Some projects that have historically been termed content management systems have begun to take on the roles of higher-layer web application frameworks. For instance, Drupal's structure provides a minimal core whose function is extended through modules that provide functions generally associated with web application frameworks. The Solodev and Joomla platforms provide a set of APIs to build web and command-line applications. However, it is debatable whether "management of content" is the primary value of such systems, especially when some, like SilverStripe, provide an object-oriented MVC framework. Add-on modules now enable these systems to function as full-fledged applications beyond the scope of content management. They may provide functional APIs, functional frameworks, coding standards, and many of the functions traditionally associated with Web application frameworks.
Web caching is the caching of web documents in order to reduce bandwidth usage, server load, and perceived " lag". A web cache stores copies of documents passing through it; subsequent requests may be satisfied from the cache if certain conditions are met. Some application frameworks provide mechanisms for caching documents and bypassing various stages of the page's preparation, such as database access or template interpretation.
Some web application frameworks come with authentication and authorization frameworks, that enable the web server to identify the users of the application, and restrict access to functions based on some defined criteria. Drupal is one example that provides role-based access to pages, and provides a web-based interface for creating users and assigning them roles.
Many web application frameworks create a unified API to a database backend, enabling web applications to work with a variety of databases with no code changes, and allowing programmers to work with higher-level concepts. For higher performance, database connections should be pooled as e.g. AOLserver does. Additionally, some object-oriented frameworks contain mapping tools to provide object-relational mapping, which maps objects to tuples.
Some frameworks minimize web application configuration through the use of introspection and/or following well-known conventions. For example, many Java frameworks use Hibernate as a persistence layer, which can generate a database schema at runtime capable of persisting the necessary information. This allows the application designer to design business objects without needing to explicitly define a database schema. Frameworks such as Ruby on Rails can also work in reverse, that is, define properties of model objects at runtime based on a database schema.
Other features web application frameworks may provide include transactional support and database migration tools.
A framework's URL mapping facility is the mechanism by which the framework interprets URLs. Some frameworks, such as Drupal and Django, match the provided URL against pre-determined patterns using regular expressions, while some others use URL rewriting to translate the provided URL into one that the underlying engine will recognize. Another technique is that of graph traversal such as used by Zope, where a URL is decomposed in steps that traverse an object graph (of models and views).
A URL mapping system that uses pattern matching or URL rewriting allows more " friendly URLs" to be used, increasing the simplicity of the site and allowing for better indexing by search engines. For example, a URL that ends with "/page.cgi?cat=science&topic=physics" could be changed to simply "/page/science/physics". This makes the URL easier for people to read and hand write, and provides search engines with better information about the structural layout of the site. A graph traversal approach also tends to result in the creation of friendly URLs. A shorter URL such as "/page/science" tends to exist by default as that is simply a shorter form of the longer traversal to "/page/science/physics".
Ajax, shorthand for "", is a web development technique for creating web applications. The intent is to make web pages feel more responsive by exchanging small amounts of data with the server behind the scenes, so that the entire web page does not have to be reloaded each time the user requests a change. This is intended to increase a web page's interactivity, speed, and usability.
Due to the complexity of Ajax programming in JavaScript, there are numerous Ajax frameworks that exclusively deal with Ajax support. Some Ajax frameworks are even embedded as a part of larger frameworks. For example, the jQuery JavaScript library is included in Ruby on Rails.
With the increased interest in developing " Web 2.0" rich media applications, the complexity of programming directly in Ajax and JavaScript has become so apparent that compiler technology has stepped in, to allow developers to code in high-level languages such as Java, Python and Ruby. The first of these compilers was Morfik followed by Google Web Toolkit, with ports to Python and Ruby in the form of Pyjamas and RubyJS following some time after. These compilers and their associated widget set libraries make the development of rich media Ajax applications much more akin to that of developing desktop applications.
Some frameworks provide tools for creating and providing web services. These utilities may offer similar tools as the rest of the web application.
A number of newer Web 2.0 RESTful frameworks are now providing resource-oriented architecture (ROA) infrastructure for building collections of resources in a sort of Semantic Web ontology, based on concepts from Resource Description Framework (RDF).

I had a nerdy conversation on what might be the next mainstream framework for building web products, and in particular whether the node.js community would ultimately create this framework, or if node.js will just be a fad. This blog post is a bit of a deviation from my usual focus around marketing, so just ignore if you have no interest in the area.
Here's the summary:
- Programming languages/frameworks are like marketplaces - they have network effects
- Rails, PHP, and Visual Basic were all successful because they made it easy to build form-based applications
- Form-based apps are a popular/dominant design pattern
- The web is moving to products with real-time updates, but building real-time apps hard
- Node.js could become a popular framework by making it dead simple to create modern, real-time form-based apps
- Node.js will be niche if it continues to emphasize Javascript purity or high-scalability
The longer argument below:
Large communities of novice/intermediate programmers are important
One of the biggest technology decisions for building a new product is the choice of development language and framework. Right now for web products, the most popular choice is Ruby on Rails - it's used to build some of the most popular websites in the world, including Github, Scribd, Groupon, and Basecamp.
Programming languages are like marketplaces - you need a large functional community of people both demanding and contributing code, documentation, libraries, consulting dollars, and more. It's critical that these marketplaces have scale - it needs to appeal to the large ecosystem of novices, freelancers and consultants that constitute the vast majority of programmers in the world. It turns out, just because a small # of Stanford-trained Silicon Valley expert engineers use something doesn't guarantee success.
Before Rails, the most popular language for the web was PHP, which had a similar value proposition - it was easy to build websites really fast, and it was used by a large group of novice/intermediate programmers as well. This includes a 19-yo Mark Zuckerberg to build the initial version of Facebook. Although PHP gained the reputation of churning out spaghetti code, the ability for people to start by writing HTML and then start adding application logic all in one file made it extremely convenient for development.
And even before Rails and PHP, it was Visual Basic that engaged this same development community. It appealed to novice programmers who could quickly set up an application by dragging-and-dropping controls, write application logic with BASIC, etc.
I think there's a unifying pattern that explains much of the success of these three frameworks.
The power of form-based applications
The biggest "killer app" for all of these languages is how easy it is to build the most common application that mainstream novice-to-intermediate programmers are paid to build: Basic form-based applications.
These kinds of apps let you do a some basic variation of:
- Give the user a form for data-entry
- Store this content in a database
- Edit, view, and delete entries from this database
It turns out that this describes a very high % of useful applications, particularly in business contexts including addressbooks, medical records, event-management, but also consumer applications like blogs, photo-sharing, Q&A, etc. Because of the importance of products in this format, it's no surprise one of Visual Basic's strongest value props was a visual form building tool.
Similarly, what drove a lot of the buzz behind Rails's initial was a screencast below:
How to build a blog engine in 15 min with Rails (presented in 2005)
Even if you haven't done any programming, it's worthwhile to watch the above video to get a sense for how magical it is to get a basic form-based application up and running in Rails. You can get the basics up super quickly. The biggest advantages in using Rails are the built-in data validation and how easy it is to create usable forms that create/update/delete entries in a database.
Different languages/frameworks have different advantages - but easy form-based apps are key
The point is, every new language/framework that gets buzz has some kind of advantage over others- but sometimes these advantages are esoteric and sometimes they tap into a huge market of developers who are all trying to solve the same problem. In my opinion, if a new language primarily helps solve scalability problems, but is inferior in most other respects, then it will fail to attract a mainstream audience. This is because most products don't have to deal with scalability issues, though there's no end to programmers who pick technologies dedicated to scale just in case! But much more often than not, it's all just aspirational.
Contrast this to a language lets you develop on iOS and reach its huge audience - no matter how horrible it is, people will flock to it.
Thus, my big prediction is:
The next dominant web framework will be the one that allows you to build form-based apps that are better and easier than Rails
Let's compare this idea with one of the most recent frameworks/languages that has gotten a ton of buzz is node.js. I've been reading a bit about it but haven't used it much - so let me caveat everything in the second half with my post with that. Anyway, based on what I've seen there's a bunch of different value props ascribed to its use:
- Build server-side applications with Javascript, so you don't need two languages in the backend and frontend
- High-performance/scalability
- Allows for easier event-driven applications
A lot of the demo applications that are built seem to revolve around chat, which is easy to build in node but harder to build in Rails. Ultimately though, in its current form, there's a lot missing from what would be required for node.js to hit the same level of popularity as Rails, PHP, or Visual Basic for that. I'd argue that the first thing that the node.js community has to do is to drive towards a framework that makes modern form-based applications dead simple to build.
What would make a framework based on node.js more mainstream?
Right now, modern webapps like Quora, Asana, Google Docs, Facebook, Twitter, and others are setting the bar high for sites that can reflect changes in data across multiple users in real-time. However, building a site like this in Rails is extremely cumbersome in many ways that the node.js community may be able to solve more fundamentally.
That's why I'd love to see a "Build a blog engine in 15 minutes with node.js" that proves that node could become the best way to build modern form-based applications in the future. In order to do this, I think you'd have to show:
- Baseline functionality around scaffolding that makes it as easy as Rails
- Real-time updates for comment counts, title changes, etc that automatically show across any viewers of the blog
- Collaborative editing of a single blog post
- Dead simple implementation of a real-time feed driving the site's homepage
All of the above features are super annoying to implement in Rails, yet could be easy to do in node. It would be a huge improvement.
Until then, I think people will still continue to mostly build in Rails with a large contingent going to iOS - the latter not due to the superiority of the development platform, but rather because that's what is needed to access iOS users.
UPDATE: I just saw Meteor on Hacker News which looks promising. Very cool.
PS. Get new essays sent to your inbox
Get my weekly newsletter covering what's happening in Silicon Valley, focused on startups, marketing, and mobile.






PHP Freaks is a website dedicated to learning and teaching PHP. Here you will find a forum consisting of 132,227 members who have posted a total of 1,379,780 posts on the forums. Additionally, we have tutorials covering various aspects of PHP and you will find news syndicated from other websites so you can stay up-to-date. Along with the tutorials, the developers on the forum will be able to help you with your scripts, or you may perhaps share your knowledge so others can learn from you.
Django is a high-level Python Web framework that encourages rapid development and clean, pragmatic design.
Developed by a fast-moving online-news operation, Django was designed to handle two challenges: the intensive deadlines of a newsroom and the stringent requirements of the experienced Web developers who wrote it. It lets you build high-performing, elegant Web applications quickly.
Django focuses on automating as much as possible and adhering to the DRY principle.
Dive in by reading the overview →
When you're ready to code, read the installation guide and tutorial.
The Django framework
Object-relational mapper
Define your data models entirely in Python. You get a rich, dynamic database-access API for free - but you can still write SQL if needed.
Automatic admin interface
Save yourself the tedious work of creating interfaces for people to add and update content. Django does that automatically, and it's production-ready.
Elegant URL design
Design pretty, cruft-free URLs with no framework-specific limitations. Be as flexible as you like.
Template system
Use Django's powerful, extensible and designer-friendly template language to separate design, content and Python code.
Cache system
Hook into memcached or other cache frameworks for super performance - caching is as granular as you need.
Internationalization
Django has full support for multi-language applications, letting you specify translation strings and providing hooks for language-specific functionality.
Download
Open source, BSD license
Documentation
Sites that use Django


Bobo is a light-weight framework for creating WSGI web applications.
It's goal is to be easy to learn and remember.
It provides 2 features:
- Mapping URLs to objects
- Calling objects to generate HTTP responses
It doesn't have a templateing language, a database integration layer, or a number of other features that can be provided by WSGI middle-ware or application-specific libraries.
Bobo builds on other frameworks, most notably WSGI and WebOb.
Bobo can be installed in the usual ways, including using the setup.py install command. You can, of course, use Easy Install, Buildout, or pip.
To use the setup.py install command, download and unpack the source distribution and run the setup script:
To run bobo's tests, just use the test command:
You can do this before or after installation.
Bobo works with Python 2.4, 2.5, and 2.6. Python 3.0 support is planned. Of course, when using Python 2.4 and 2.5, class decorator syntax can't be used. You can still use the decorators by calling them with a class after a class is created.
Let's create a minimal web application, "hello world". We'll put it in a file named "hello.py":
This application creates a single web resource, "/hello.html", that simply outputs the text "Hello world".
Bobo decorators, like used in the example above control how URLs are mapped to objects. They also control how functions are called and returned values converted to web responses. If a function returns a string, it's assumed to be HTML and used to construct a response. You can control the content type used by passing a content_type keyword argument to the decorator.
Let's try out our application. Assuming that bobo's installed, you can run the application on port 8080 using [1]:
This will start a web server running on localhost port 8080. If you visit:
http://localhost:8080/hello.html
you'll get the greeting:
The URL we used to access the application was determined by the name of the resource function and the content type used by the decorator, which defaults to "text/html; charset=UTF-8". Let's change the application so we can use a URL like:
We'll do this by providing a URL path:
Here, we passed a path to the decorator. We used a '/' string, which makes a URL like the one above work. (We also omitted the import for brevity.)
We don't need to restart the server to see our changes. The bobo development server automatically reloads the file if it changes.
As its name suggests, the decorator is meant to work with resources that return information, possibly using form data. Let's modify the application to allow the name of the person to greet to be given as form data:
If a function accepts named arguments, then data will be supplied from form data. If we visit:
http://localhost:8080/?name=Sally
We'll get the output:
The decorator will accept , and requests. It's appropriate when server data aren't modified. To accept form data and modify data on a server, you should use the decorator. The decorator works like the decorator accept that it only allows and requests and won't pass data provided in a query string as function arguments.
The and decorators are convenient when you want to just get user input passed as function arguments. If you want a bit more control, you can also get the request object by defining a bobo_request parameter:
The request object gives full access to all of the form data, as well as other information, such as cookies and input headers.
The and decorators introspect the function they're applied to. This means they can't be used with callable objects that don't provide function meta data. There's a low-level decorator, that does no introspection and can be used with any callable:
The decorator always passes the request object as the first positional argument to the callable it's given.
The , , and decorators provide automatic response generation when the value returned by an application isn't a object. The generation of the response is controlled by the content type given to the content_type decorator parameter.
If an application returns a string, then a response is constructed using the string with the content type.
If an application doesn't return a response or a string, then the handling depends on whether or not the content type is 'application/json . For 'application/json , the returned value is marshalled to JSON using the (or simplejson ) module, if present. If the module isn't importable, or if marshaling fails, then an exception will be raised.
If an application returns a unicode string and the content type isn't 'application/json' , the string is encoded using the character set given in the content_type, or using the UTF-8 encoding, if the content type doesn't include a charset parameter.
If an application returns a non-response non-string result and the content type isn't 'application/json' , then an exception is raised.
If an application wants greater control over a response, it will generally want to construct a webob.Response object and return that.
We saw earlier that we could control the URLs used to access resources by passing a path to a decorator. The path we pass can specify a multi-level URL and can have placeholders, which allow us to pass data to the resource as part of the URL.
Here, we modify the hello application to let us pass the name of the greeter in the URL:
Now, to access the resource, we use a URL like:
http://localhost:8080/greeters/myapp?name=Sally
for which we get the output:
Hello Sally! My name is myapp.
We call these paths because they use a syntax inspired loosely by the Ruby on Rails Routing system.
You can have any number of placeholders or constant URL paths in a route. The values associated with the placeholders will be made available as function arguments.
If a placeholder is followed by a question mark, then the route segment is optional. If we change the hello example:
we can use the URL:
http://localhost:8080/greeters?name=Sally
for which we get the output:
Hello Sally! My name is Bobo.
Note, however, if we use the URL:
http://localhost:8080/greeters/?name=Sally
we get the output:
Hello Sally! My name is .
Placeholders must be legal Python identifiers. A placeholder may be followed by an extension. For example, we could use:
Here, we've said that the name must have an ".html" suffix. To access the function, we use a URL like:
http://localhost:8080/greeters/myapp.html?name=Sally
And get:
Hello Sally! My name is myapp.
If the placeholder is optional:
Then we can use a URL like:
http://localhost:8080/greeters?name=Sally
or:
http://localhost:8080/greeters/jim.html?name=Sally
Subroutes
Sometimes, you want to split URL matching into multiple steps. You might do this to provide cleaner abstractions in your application, or to support more flexible resource organization. You can use the subroute decorator to do this. The subroute decorator decorates a callable object that returns a resource. The subroute uses the given route to match the beginning of the request path. The resource returned by the callable is matched against the remainder of the path. Let's look at an example:
With this example, if we visit:
http://localhost:8080/employees/1/summary.html
We'll get the summary for a user. The URL will be matched in 2 steps. First, the path /employees/1 will match the subroute. The class is called with the request and employee id. Then the routes defined for the individual methods are searched. The remainder of the path,/summary.html , matches the route for the summary method. (Note that we provided two decorators for the summary method, which allows us to get to it two ways.) The methods were scanned for routes because we used the keyword argument.
The method has a route that is an empty string. This is a special case that handles an empty path after matching a subroute. The base method will be called for a URL like:
http://localhost:8080/employees/1
which would redirect to:
http://localhost:8080/employees/1/
The method defines another subroute. Because we left off the route path, the method name is used. This returns a Folder instance. Let's look at the Folder class:
The and classes use the decorator. The class decorator scans a class to make routes defined for it's methods available. Using the decorator is equivalent to using the keyword with decorator [2]. Now consider a URL:
http://localhost:8080/employees/1/documents/hobbies/sports.html
which outputs:
I like to ski.
The URL is matched in multiple steps:
- The path /employees/1 matches the class.
- The path matches the method, which returns a using the employee documents dictionary.
- The path matches the method of the class, which returns the dictionary from the documents folder.
- The path /sports.html also matches the method, which returns a using the text for thesports.html key.
5, The empty path matches the method of the class.
Of course, the employee document tree can be arbitrarily deep.
The decorator can be applied to any callable object that takes a request and route data and returns a resource.
Methods and REST
When we define a resource, we can also specify the HTTP methods it will handle. The and decorators will handle GET, HEAD and POST methods by default. The decorator handles POST and PUT methods. You can specify one or more methods when using the , , and decorators:
If multiple resources (resource, query, or post) in a module or class have the same route strings, the resource used will be selected based on both the route and the methods allowed. (If multiple resources match a request, the first one defined will be used [3].)
The ability to provide handlers for specific methods provides support for the REST architectural style. .. _configuration:
The bobo server makes it easy to get started. Just run it with a source file and off you go. When you're ready to deploy your application, you'll want to put your source code in an importable Python module (or package). Bobo publishes modules, not source files. The bobo server provides the convenience of converting a source file to a module.
The bobo command-line server is convenient for getting started, but production applications will usually be configured with selected servers and middleware using Paste Deployment. Bobo includes a Paste Deployment application implementation. To use bobo with Paste Deployment, simply define an application section using the bobo egg:
[app:main] use = egg:bobo bobo_resources = helloapp bobo_configure = helloapp:config employees_database = /home/databases/employees.db [server:main] use = egg:Paste#http host = localhost port = 8080
In this example, we're using the HTTP server that is built into Paste.
The application section () contains bobo options, as well as application-specific options. In this example, we used the bobo_resources option to specify that we want to use resources found in the hellowapp module, and the bobo_configure option to specify a configuration handler to be called with configuration data.
You can put application-specific options in the application section, which can be used by configuration handlers. You can provide one or more configuration handlers using the bobo_configure option. Each configuration handler is specified as a module name and global name [4] separated by a colon.
Configuration handlers are called with a mapping object containing options from the application section and from the DEFAULT section, if present, with application options taking precedence.
To start the server, you'll run the paster script installed with PasteScript and specify the name of your configuration file:
You'll need to install Paste Script to use bobo with Paste Deployment.
See Assembling and running the example with Paste Deployment and Paste Script for a complete example.
Bottle is a fast, simple and lightweight WSGI micro web-framework for Python. It is distributed as a single file module and has no dependencies other than the Python Standard Library.
- Routing: Requests to function-call mapping with support for clean and dynamic URLs.
- Templates: Fast and pythonic built-in template engine and support for mako, jinja2 and cheetah templates.
- Utilities: Convenient access to form data, file uploads, cookies, headers and other HTTP-related metadata.
- Server: Built-in HTTP development server and support for paste, fapws3, bjoern, Google App Engine, cherrypy or any other WSGI capable HTTP server.
Example: "Hello World" in a bottle
Run this script or paste it into a Python console, then point your browser to http://localhost:8080/hello/world. That's it.
Download and Install
Install the latest stable release via PyPI () or download bottle.py (unstable) into your project directory. There are no hard [1] dependencies other than the Python standard library. Bottle runs with Python 2.5+ and 3.x.
User's Guide
Start here if you want to learn how to use the bottle framework for web development. If you have any questions not answered here, feel free to ask the mailing list.
Knowledge Base
A collection of articles, guides and HOWTOs.
Development and Contribution
These chapters are intended for developers interested in the bottle development and release workflow.
License
Code and documentation are available according to the MIT License:
Copyright (c) 2012, Marcel Hellkamp. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
The Bottle logo however is NOT covered by that license. It is allowed to use the logo as a link to the bottle homepage or in direct context with the unmodified library. In all other cases please ask first.
Footnotes







Why wait? It's free!
Sign up now and get a free Nerd Life shirt
Get immediate code-level visibility and build faster, more reliable web and mobile applications.
Create Free AccountNo credit card required * No commitment

Web Application Monitoring
New Relic is the only dashboard you need to keep an eye on application health and availability. Real user monitoring, server utilization, code-level diagnostics, and more. Get direct visibility into your Ruby, PHP, Java, .NET, Python and Node.js apps. New Relic is a better way to monitor and boost performance for your entire web app environment. Complete visibility anytime you want it.
Learn More About Web App MonitoringWith Web App Monitoring you can...
Get Started Today
Sign up and get a free T-shirt
Real User Monitoring
Get browser performance data directly from real end-users and see exactly what their experiences are by monitoring transactions traces, JavaScript rendering speed and network latency all from their perspective.
Server Monitoring
Get critical web server resource data in the context of real-time application performance, whether your apps are deployed in the cloud or in your data center. It's powerful, and it's free.
Loved & Trusted
New Relic captures 150 billion metrics each day from millions of apps
Mobile Application Monitoring
The same powerful New Relic performance data is now available for your native iOS and Android apps. For the first time ever, see the end-to-end performance of your app with deep and actionable insight into real users, sessions and finger swipes as they happen.
Works with the following languages:
It's more than just code that can slow down your app.
Your App Code
We're sure your code is awesome, Now track activity, get alerts and create custom metrics.
Network Performance
Is it a background service or a carrier slowing you down? Is it regional or global? Never wonder again.
Device Profile
Know what devices and operating systems to focus on, track user activity, and get performance breakdowns.
End-to-End Visibility
Slow code on the device, non-responsive API calls, slow backend services. Alert the right team immediately.
Plugins
New Relic's open SaaS Platform allows you to download and use customized plugins so you can get visibility into your entire technology stack within our first-class UI and data visualizations. Don't see an app you want? Rapidly and easily create and deploy new plugins to optimize your complete app environment.
Learn More About PluginsIt's free, it's fast. Get the insights you need to improve your application's performance.



Michael Hartl
Contents
My former company (CD Baby) was one of the first to loudly switch to Ruby on Rails, and then even more loudly switch back to PHP (Google me to read about the drama). This book by Michael Hartl came so highly recommended that I had to try it, and the Ruby on Rails Tutorial is what I used to switch back to Rails again.
Though I've worked my way through many Rails books, this is the one that finally made me "get" it. Everything is done very much "the Rails way"-a way that felt very unnatural to me before, but now after doing this book finally feels natural. This is also the only Rails book that does test-driven development the entire time, an approach highly recommended by the experts but which has never been so clearly demonstrated before. Finally, by including Git, GitHub, and Heroku in the demo examples, the author really gives you a feel for what it's like to do a real-world project. The tutorial's code examples are not in isolation.
The linear narrative is such a great format. Personally, I powered through the Rails Tutorial in three long days, doing all the examples and challenges at the end of each chapter. Do it from start to finish, without jumping around, and you'll get the ultimate benefit.
Enjoy!
The Ruby on Rails Tutorial owes a lot to my previous Rails book, RailsSpace, and hence to my coauthor Aurelius Prochazka. I'd like to thank Aure both for the work he did on that book and for his support of this one. I'd also like to thank Debra Williams Cauley, my editor on both RailsSpace and the Ruby on Rails Tutorial; as long as she keeps taking me to baseball games, I'll keep writing books for her.
I'd like to acknowledge a long list of Rubyists who have taught and inspired me over the years: David Heinemeier Hansson, Yehuda Katz, Carl Lerche, Jeremy Kemper, Xavier Noria, Ryan Bates, Geoffrey Grosenbach, Peter Cooper, Matt Aimonetti, Gregg Pollack, Wayne E. Seguin, Amy Hoy, Dave Chelimsky, Pat Maddox, Tom Preston-Werner, Chris Wanstrath, Chad Fowler, Josh Susser, Obie Fernandez, Ian McFarland, Steven Bristol, Pratik Naik, Sarah Mei, Sarah Allen, Wolfram Arnold, Alex Chaffee, Giles Bowkett, Evan Dorn, Long Nguyen, James Lindenbaum, Adam Wiggins, Tikhon Bernstam, Ron Evans, Wyatt Greene, Miles Forrest, the good people at Pivotal Labs, the Heroku gang, the thoughtbot guys, and the GitHub crew. Finally, many, many readers-far too many to list-have contributed a huge number of bug reports and suggestions during the writing of this book, and I gratefully acknowledge their help in making it as good as it can be.
Michael Hartl is the author of the Ruby on Rails Tutorial, the leading introduction to web development with Ruby on Rails. His prior experience includes writing and developing RailsSpace, an extremely obsolete Rails tutorial book, and developing Insoshi, a once-popular and now-obsolete social networking platform in Ruby on Rails. In 2011, Michael received a Ruby Hero Award for his contributions to the Ruby community. He is a graduate of Harvard College, has a Ph.D. in Physics from Caltech, and is an alumnus of the Y Combinator entrepreneur program.
Ruby on Rails Tutorial: Learn Web Development with Rails. Copyright © 2013 by Michael Hartl. All source code in the Ruby on Rails Tutorial is available jointly under the MIT License and the Beerware License.
The MIT License Copyright (c) 2013 Michael Hartl Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
/* * ---------------------------------------------------------------------------- * "THE BEER-WARE LICENSE" (Revision 42): * Michael Hartl wrote this code. As long as you retain this notice you * can do whatever you want with this stuff. If we meet some day, and you think * this stuff is worth it, you can buy me a beer in return. * ---------------------------------------------------------------------------- */
Welcome to the Ruby on Rails Tutorial. The goal of this book is to be the best answer to the question, "If I want to learn web development with Ruby on Rails, where should I start?" By the time you finish the Ruby on Rails Tutorial, you will have all the skills you need to develop and deploy your own custom web applications with Rails. You will also be ready to benefit from the many more advanced books, blogs, and screencasts that are part of the thriving Rails educational ecosystem. Finally, since the Ruby on Rails Tutorial uses Rails 4, the knowledge you gain here represents the state of the art in web development. (The most up-to-date version of the Ruby on Rails Tutorial can be found on the book's website at http://railstutorial.org/; if you are reading this book offline, be sure to check the online version of the Rails Tutorial book at http://railstutorial.org/book for the latest updates.)
( Note: The present volume is the Rails 4.0 version of the book, which means that it has been revised to be compatible with Rails 4.0, but it is not yet a new edition because the changes in Rails don't yet justify it. From the perspective of an introductory tutorial, the differences between Rails 4.0 and the previous version, Rails 3.2, are slight. Indeed, although there are a large number of miscellaneous small changes ( Box 1.1), for our purposes there is only one significant difference, a new security technique called strong parameters, covered in Section 7.3.2. Once the changes in Rails justify the effort, I plan to prepare a full new edition of the Rails Tutorial, including coverage of topics such as Turbolinks and Russian doll caching, as well as some new aspects of RSpec, such as feature specs.)
It's worth emphasizing that the goal of this book is not merely to teach Rails, but rather to teach web development with Rails, which means acquiring (or expanding) the skills needed to develop software for the World Wide Web. In addition to Ruby on Rails, this skillset includes HTML & CSS, databases, version control, testing, and deployment. To accomplish this goal, the Ruby on Rails Tutorial takes an integrated approach: you will learn Rails by example by building a substantial sample application from scratch. As Derek Sivers notes in the foreword, this book is structured as a linear narrative, designed to be read from start to finish. If you are used to skipping around in technical books, taking this linear approach might require some adjustment, but I suggest giving it a try. You can think of the Ruby on Rails Tutorial as a video game where you are the main character, and where you level up as a Rails developer in each chapter. (The exercises are the minibosses.)
In this first chapter, we'll get started with Ruby on Rails by installing all the necessary software and by setting up our development environment ( Section 1.2). We'll then create our first Rails application, called (appropriately enough) first_app. The Rails Tutorial emphasizes good software development practices, so immediately after creating our fresh new Rails project we'll put it under version control with Git ( Section 1.3). And, believe it or not, in this chapter we'll even put our first app on the wider web by deploying it to production ( Section 1.4).
In Chapter 2, we'll make a second project, whose purpose is to demonstrate the basic workings of a Rails application. To get up and running quickly, we'll build this demo app (called demo_app) using scaffolding ( Box 1.2) to generate code; since this code is both ugly and complex, Chapter 2 will focus on interacting with the demo app through its URIs (often called URLs) using a web browser.
The rest of the tutorial focuses on developing a single large sample application (called sample_app), writing all the code from scratch. We'll develop the sample app using test-driven development (TDD), getting started in Chapter 3 by creating static pages and then adding a little dynamic content. We'll take a quick detour in Chapter 4 to learn a little about the Ruby language underlying Rails. Then, in Chapter 5 through Chapter 9, we'll complete the foundation for the sample application by making a site layout, a user data model, and a full registration and authentication system. Finally, in Chapter 10 and Chapter 11 we'll add microblogging and social features to make a working example site.
The final sample application will bear more than a passing resemblance to a certain popular social microblogging site-a site which, coincidentally, was also originally written in Rails. Though of necessity our efforts will focus on this specific sample application, the emphasis throughout the Rails Tutorial will be on general principles, so that you will have a solid foundation no matter what kinds of web applications you want to build.
Since its debut in 2004, Ruby on Rails has rapidly become one of the most powerful and popular frameworks for building dynamic web applications. Everyone from scrappy startups to huge companies have used Rails: 37signals, GitHub, Shopify, Scribd, Twitter, Disney, Hulu, the Yellow Pages-the list of sites using Rails goes on and on. There are also many web development shops that specialize in Rails, such as ENTP, thoughtbot, Pivotal Labs, and Hashrocket, plus innumerable independent consultants, trainers, and contractors.
What makes Rails so great? First of all, Ruby on Rails is 100% open-source, available under the permissive MIT License, and as a result it also costs nothing to download or use. Rails also owes much of its success to its elegant and compact design; by exploiting the malleability of the underlying Ruby language, Rails effectively creates a domain-specific language for writing web applications. As a result, many common web programming tasks-such as generating HTML, making data models, and routing URLs-are easy with Rails, and the resulting application code is concise and readable.
Rails also adapts rapidly to new developments in web technology and framework design. For example, Rails was one of the first frameworks to fully digest and implement the REST architectural style for structuring web applications (which we'll be learning about throughout this tutorial). And when other frameworks develop successful new techniques, Rails creator David Heinemeier Hansson and the Rails core team don't hesitate to incorporate their ideas. Perhaps the most dramatic example is the merger of Rails and Merb, a rival Ruby web framework, so that Rails now benefits from Merb's modular design, stable API, and improved performance.
Finally, Rails benefits from an unusually enthusiastic and diverse community. The results include hundreds of open-source contributors, well-attended conferences, a huge number of gems (self-contained solutions to specific problems such as pagination and image upload), a rich variety of informative blogs, and a cornucopia of discussion forums and IRC channels. The large number of Rails programmers also makes it easier to handle the inevitable application errors: the "Google the error message" algorithm nearly always produces a relevant blog post or discussion-forum thread.
The Rails Tutorial contains integrated tutorials not only for Rails, but also for the underlying Ruby language, the RSpec testing framework, HTML, CSS, a small amount of JavaScript, and even a little SQL. This means that, no matter where you currently are in your knowledge of web development, by the time you finish this tutorial you will be ready for more advanced Rails resources, as well as for the more systematic treatments of the other subjects mentioned. It also means that there's a lot of material to cover; if you don't already have much experience programming computers, you might find it overwhelming. The comments below contain some suggestions for approaching the Rails Tutorial depending on your background.
All readers: One common question when learning Rails is whether to learn Ruby first. The answer depends on your personal learning style and how much programming experience you already have. If you prefer to learn everything systematically from the ground up, or if you have never programmed before, then learning Ruby first might work well for you, and in this case I recommend Beginning Ruby by Peter Cooper. On the other hand, many beginning Rails developers are excited about making web applications, and would rather not slog through a 500-page book on pure Ruby before ever writing a single web page. In this case, I recommend following the short interactive tutorial at Try Ruby, and then optionally do the free tutorial at Rails for Zombies to get a taste of what Rails can do.
Another common question is whether to use tests from the start. As noted in the introduction, the Rails Tutorial uses test-driven development (also called test-first development), which in my view is the best way to develop Rails applications, but it does introduce a substantial amount of overhead and complexity. If you find yourself getting bogged down by the tests, I suggest either skipping them on a first reading or (even better) using them as a tool to verify your code's correctness without worrying about how they work. This latter strategy involves creating the necessary test files (called specs) and filling them with the test code exactly as it appears in the book. You can then run the test suite (as described in Chapter 5) to watch it fail, then write the application code as described in the tutorial, and finally re-run the test suite to watch it pass.
Inexperienced programmers: The Rails Tutorial is not aimed principally at beginning programmers, and web applications, even relatively simple ones, are by their nature fairly complex. If you are completely new to web programming and find the Rails Tutorial too difficult, I suggest learning the basics of HTML and CSS and then giving the Rails Tutorial another go. (Unfortunately, I don't have a personal recommendation here, but Head First HTML looks promising, and one reader recommends CSS: The Missing Manual by David Sawyer McFarland.) You might also consider reading the first few chapters of Beginning Ruby by Peter Cooper, which starts with sample applications much smaller than a full-blown web app. That said, a surprising number of beginners have used this tutorial to learn web development, so I suggest giving it a try, and I especially recommend the Rails Tutorial screencast series to give you an "over-the-shoulder" look at Rails software development.
Experienced programmers new to web development: Your previous experience means you probably already understand ideas like classes, methods, data structures, etc., which is a big advantage. Be warned that if your background is in C/C++ or Java, you may find Ruby a bit of an odd duck, and it might take time to get used to it; just stick with it and eventually you'll be fine. (Ruby even lets you put semicolons at the ends of lines if you miss them too much.) The Rails Tutorial covers all the web-specific ideas you'll need, so don't worry if you don't currently know a POST from a PATCH.
Experienced web developers new to Rails: You have a great head start, especially if you have used a dynamic language such as PHP or (even better) Python. The basics of what we cover will likely be familiar, but test-driven development may be new to you, as may be the structured REST style favored by Rails. Ruby has its own idiosyncrasies, so those will likely be new, too.
Experienced Ruby programmers: The set of Ruby programmers who don't know Rails is a small one nowadays, but if you are a member of this elite group you can fly through this book and then move on to developing applications of your own.
Inexperienced Rails programmers: You've perhaps read some other tutorials and made a few small Rails apps yourself. Based on reader feedback, I'm confident that you can still get a lot out of this book. Among other things, the techniques here may be more up-to-date than the ones you picked up when you originally learned Rails.
Experienced Rails programmers: This book is unnecessary for you, but many experienced Rails developers have expressed surprise at how much they learned from this book, and you might enjoy seeing Rails from a different perspective.
After finishing the Ruby on Rails Tutorial, I recommend that experienced programmers read The Well-Grounded Rubyist by David A. Black, Eloquent Ruby by Russ Olsen, or The Ruby Way by Hal Fulton, which is also fairly advanced but takes a more topical approach.
At the end of this process, no matter where you started, you should be ready for the many more intermediate-to-advanced Rails resources out there. Here are some I particularly recommend:
Before moving on with the rest of the introduction, I'd like to take a moment to address the one issue that dogged the Rails framework the most in its early days: the supposed inability of Rails to "scale"-i.e., to handle large amounts of traffic. Part of this issue relied on a misconception; you scale a site, not a framework, and Rails, as awesome as it is, is only a framework. So the real question should have been, "Can a site built with Rails scale?" In any case, the question has now been definitively answered in the affirmative: some of the most heavily trafficked sites in the world use Rails. Actually doing the scaling is beyond the scope of just Rails, but rest assured that if your application ever needs to handle the load of Hulu or the Yellow Pages, Rails won't stop you from taking over the world.
The conventions in this book are mostly self-explanatory. In this section, I'll mention some that may not be.
Both the HTML and PDF editions of this book are full of links, both to internal sections (such as Section 1.2) and to external sites (such as the main Ruby on Rails download page).
Many examples in this book use command-line commands. For simplicity, all command line examples use a Unix-style command line prompt (a dollar sign), as follows:
Windows users should understand that their systems will use the analogous angle prompt >:
On Unix systems, some commands should be executed with sudo, which stands for "substitute user do". By default, a command executed with sudo is run as an administrative user, which has access to files and directories that normal users can't touch, such as in this example from Section 1.2.2:
Most Unix/Linux/OS X systems require sudo by default, unless you are using Ruby Version Manager as suggested in Section 1.2.2.3; in this case, you would type this instead:
Rails comes with lots of commands that can be run at the command line. For example, in Section 1.2.5 we'll run a local development web server as follows:
As with the command-line prompt, the Rails Tutorial uses the Unix convention for directory separators (i.e., a forward slash /). My Rails Tutorial sample application, for instance, lives in
/Users/mhartl/rails_projects/sample_app
On Windows, the analogous directory would be
The root directory for any given app is known as the Rails root, but this terminology is confusing and many people mistakenly believe that the "Rails root" is the root directory for Rails itself. For clarity, the Rails Tutorial will refer to the Rails root as the application root, and henceforth all directories will be relative to this directory. For example, the config directory of my sample application is
/Users/mhartl/rails_projects/sample_app/config
The application root directory here is everything before config, i.e.,
/Users/mhartl/rails_projects/sample_app
For brevity, when referring to the file
/Users/mhartl/rails_projects/sample_app/config/routes.rb
I'll omit the application root and simply write config/routes.rb.
The Rails Tutorial often shows output from various programs (shell commands, version control status, Ruby programs, etc.). Because of the innumerable small differences between different computer systems, the output you see may not always agree exactly with what is shown in the text, but this is not cause for concern.
Some commands may produce errors depending on your system; rather than attempt the Sisyphean task of documenting all such errors in this tutorial, I will delegate to the "Google the error message" algorithm, which among other things is good practice for real-life software development. If you run into any problems while following the tutorial, I suggest consulting the resources listed on the Rails Tutorial help page.
I think of Chapter 1 as the "weeding out phase" in law school-if you can get your dev environment set up, the rest is easy to get through.
-Bob Cavezza, Rails Tutorial reader
It's time now to get going with a Ruby on Rails development environment and our first application. There is quite a bit of overhead here, especially if you don't have extensive programming experience, so don't get discouraged if it takes a while to get started. It's not just you; every developer goes through it (often more than once), but rest assured that the effort will be richly rewarded.
Considering various idiosyncratic customizations, there are probably as many development environments as there are Rails programmers, but there are at least two broad types: text editor/command line environments, and integrated development environments (IDEs). Let's consider the latter first.
The most prominent Rails IDEs are RadRails and RubyMine. I've heard especially good things about RubyMine, and one reader (David Loeffler) has assembled notes on how to use RubyMine with this tutorial. If you're comfortable using an IDE, I suggest taking a look at the options mentioned to see what fits with the way you work.
Instead of using an IDE, I prefer to use a text editor to edit text, and a command line to issue commands ( Figure 1.1). Which combination you use depends on your tastes and your platform.
- Text editor: I recommend Sublime Text 2, an outstanding cross-platform text editor that is simultaneously easy to learn and industrial-strength. Sublime Text is heavily influenced by TextMate, and in fact is compatible with most TextMate customizations, such as snippets and color schemes. (TextMate, which is available only on OS X, is still a good choice if you use a Mac.) A second excellent choice is Vim, versions of which are available for all major platforms. Sublime Text can be obtained commercially, whereas Vim can be obtained at no cost; both are industrial-strength editors, but in my experience Sublime Text is much more accessible to beginners.
- Terminal: On OS X, I recommend either use iTerm or the native Terminal app. On Linux, the default terminal is fine. On Windows, many users prefer to develop Rails applications in a virtual machine running Linux, in which case your command-line options reduce to the previous case. If developing within Windows itself, I recommend using the command prompt that comes with Rails Installer (Section 1.2.2.1).
If you decide to use Sublime Text, you might want to follow the optional setup instructions for Rails Tutorial Sublime Text. (Such configuration settings can be fiddly and error-prone, so I mainly recommend them for more advanced users; Sublime Text is an excellent choice for editing Rails applications even without the advanced setup.)
Although there are many web browsers to choose from, the vast majority of Rails programmers use Firefox, Safari, or Chrome when developing. All three browsers include a built-in "Inspect element" feature available by right- (or control-)clicking on any part of the page.
In the process of getting your development environment up and running, you may find that you spend a lot of time getting everything just right. The learning process for editors and IDEs is particularly long; you can spend weeks on Sublime Text or Vim tutorials alone. If you're new to this game, I want to assure you that spending time learning tools is normal. Everyone goes through it. Sometimes it is frustrating, and it's easy to get impatient when you have an awesome web app in your head and you just want to learn Rails already, but have to spend a week learning some weird ancient Unix editor just to get started. But, as with an apprentice carpenter striving to master the chisel or the plane, there is no subsitute for mastering the tools of your trade, and in the end the reward is worth the effort.
Practically all the software in the world is either broken or very difficult to use. So users dread software. They've been trained that whenever they try to install something, or even fill out a form online, it's not going to work. I dread installing stuff, and I have a Ph.D. in computer science.
-Paul Graham, in Founders at Work by Jessica Livingston
Now it's time to install Ruby and Rails. I've done my best to cover as many bases as possible, but systems vary, and many things can go wrong during these steps. Be sure to Google the error message or consult the Rails Tutorial help page if you run into trouble. Also, there's a new resource called Install Rails from One Month Rails that might help you if you get stuck.
Unless otherwise noted, you should use the exact versions of all software used in the tutorial, including Rails itself, if you want the same results. Sometimes minor version differences will yield identical results, but you shouldn't count on this, especially with respect to Rails versions. The main exception is Ruby itself: 1.9.3 and 2.0.0 are virtually identical for the purposes of this tutorial, so feel free to use either one.
Installing Rails on Windows used to be a real pain, but thanks to the efforts of the good people at Engine Yard-especially Dr. Nic Williams and Wayne E. Seguin-installing Rails and related software on Windows is now easy. If you are using Windows, go to Rails Installer and download the Rails Installer executable and view the excellent installation video. Double-click the executable and follow the instructions to install Git (so you can skip Section 1.2.2.2), Ruby (skip Section 1.2.2.3), RubyGems (skip Section 1.2.2.4), and Rails itself (skip Section 1.2.2.5). Once the installation has finished, you can skip right to the creation of the first application in Section 1.2.3.
Bear in mind that the Rails Installer might use a slightly different version of Rails from the one installed in Section 1.2.2.5, which might cause incompatibilities. To fix this, I am currently working with Nic and Wayne to create a list of Rails Installers ordered by Rails version number.
Much of the Rails ecosystem depends in one way or another on a version control system called Git (covered in more detail in Section 1.3). Because its use is ubiquitous, you should install Git even at this early stage; I suggest following the installation instructions for your platform at the Installing Git section of Pro Git.
The next step is to install Ruby. (This can be painful and error-prone, and I actually dread having to install new versions of Ruby, but unfortunately it's the cost of doing business.)
It's possible that your system already has Ruby installed. Try running
to see the version number. Rails 4 requires Ruby 1.9 or later and on most systems works best with Ruby 2.0. (In particular, it won't work Ruby 1.8.7.) This tutorial assumes that most readers are using Ruby 1.9.3 or 2.0.0, but Ruby 1.9.2 should work as well. Note: I've had reports from Windows users that Ruby 2.0 is sketchy, so I recommend using Ruby 1.9.3 if you're on Windows.
As part of installing Ruby, if you are using OS X or Linux I strongly recommend using Ruby Version Manager (RVM) or rbenv, which allow you to install and manage multiple versions of Ruby on the same machine. (The Pik project accomplishes a similar feat on Windows.) This is particularly important if you want to run different versions of Ruby or Rails on the same machine. Unfortunately, RVM and rbenv can't be used on the same system simultaneously, and since I've been using RVM longer that's the one I use in this tutorial. I hear great things about rbenv, though, so you should feel free to use that if you already know it or if you have access to a local rbenv expert.
As a prerequisite, OS X users may need to install the Xcode developer tools. To avoid the (huge) full installation, I recommend the much smaller Command Line Tools for Xcode.
To get started with the Ruby installation, first install RVM:
(If you have RVM installed, you should run
to ensure that you have the latest version.)
You can then get Ruby set up by examining the requirements for installing it:
On my system, I had to install the following (using Homebrew, a package management system for OS X):
On Linux, you can accomplish similar things with apt-get or yum.
I also had to install a YAML library:
Finally, I needed to tell RVM where OpenSSL was located when installing Ruby 2.0.0:
On some systems, especially on Macs using Homebrew, the location of OpenSSL may be different, and you might have to run this command instead:
Unfortunately, lots of things can go wrong along the way. I've done my best to cover some of the most common cases, but the only general solution is web searches and determination.
After installing Ruby, you should configure your system for the other software needed to run Rails applications. This typically involves installing gems, which are self-contained packages of Ruby code. Since gems with different version numbers sometimes conflict, it is often convenient to create separate gemsets, which are self-contained bundles of gems. For the purposes of this tutorial, I suggest creating a gemset called railstutorial_rails_4_0:
This command creates (--create) the gemset railstutorial_rails_4_0 associated with Ruby 2.0.0 while arranging to start using it immediately ( use) and setting it as the default (--default) gemset, so that any time we open a new terminal window the 2.0.0@railstutorial_rails_4_0 Ruby/gemset combination is automatically selected. RVM supports a large variety of commands for manipulating gemsets; see the documentation at http://rvm.beginrescueend.com/gemsets/. If you ever get stuck with RVM, running commands like these should help you get your bearings:
For more information on RVM, I also recommend taking a look at the article Ruby Version Manager (RVM) Overview for Rails Newbs.
RubyGems is a package manager for Ruby projects, and there are many useful libraries (including Rails) available as Ruby packages, or gems. Installing RubyGems should be easy once you install Ruby. In fact, if you have installed RVM, you already have RubyGems, since RVM includes it automatically:
If you don't already have it, you should download RubyGems, extract it, and then go to the rubygems directory and run the setup program:
(If you get a permissions error here, recall from Section 1.1.3 that you may have to use sudo.)
If you already have RubyGems installed, you should make sure your system uses the version used in this tutorial:
Freezing your system to this particular version will help prevent conflicts as RubyGems changes in the future.
When installing gems, by default RubyGems generates two different kinds of documentation (called ri and rdoc), but many Ruby and Rails developers find that the time to build them isn't worth the benefit. (Many programmers rely on online documentation instead of the native ri and rdoc documents.) To prevent the automatic generation of the documentation, I recommend making a gem configuration file called .gemrc in your home directory as in Listing 1.1 with the line in Listing 1.2. (The tilde "~" means "home directory", while the dot . in .gemrc makes the file hidden, which is a common convention for configuration files. )
Creating a gem configuration file.
Here subl is the command-line command to launch Sublime Text on OS X, which you can set up using the Sublime Text 2 documentation for the OS X command line. If you're on a different platform, or if you're using a different editor, you should replace this command as necessary (i.e., by double-clicking the application icon or by using an alternate command such as mate, vim, gvim, or mvim). For brevity, throughout the rest of this tutorial I'll use subl as a shorthand for "open with your favorite text editor."
Once you've installed RubyGems, installing Rails should be easy. This tutorial standardizes on Rails 4.0, which we can install as follows:
To check your Rails installation, run the following command to print out the version number:
Note: If you installed Rails using the Rails Installer in Section 1.2.2.1, there might be slight version differences. As of this writing, those differences are not relevant, but in the future, as the current Rails version diverges from the one used in this tutorial, these differences may become significant. I am currently working with Engine Yard to create links to specific versions of the Rails Installer.
If you're running Linux, you might have to install a couple of other packages at this point:
Virtually all Rails applications start the same way, by running rails new command. This handy command creates a skeleton Rails application in a directory of your choice. To get started, make a directory for your Rails projects and then run rails new to make the first application ( Listing 1.3):
As seen at the end of Listing 1.3, running rails new automatically runs the bundle install command after the file creation is done. If that step doesn't work right now, don't worry; follow the steps in Section 1.2.4 and you should be able to get it to work.
Notice how many files and directories the rails command creates. This standard directory and file structure ( Figure 1.2) is one of the many advantages of Rails; it immediately gets you from zero to a functional (if minimal) application. Moreover, since the structure is common to all Rails apps, you can immediately get your bearings when looking at someone else's code. A summary of the default Rails files appears in Table 1.1; we'll learn about most of these files and directories throughout the rest of this book. In particular, starting in Section 5.2.1 we'll discuss the app/assets directory, part of the asset pipeline that makes it easier than ever to organize and deploy assets such as cascading style sheets and JavaScript files.
After creating a new Rails application, the next step is to use Bundler to install and include the gems needed by the app. As noted briefly in Section 1.2.3, Bundler is run automatically (via bundle install) by the rails command, but in this section we'll make some changes to the default application gems and run Bundler again. This involves opening the Gemfile with your favorite text editor:
The result should look something like Listing 1.4. The code in this file is Ruby, but don't worry at this point about the syntax; Chapter 4 will cover Ruby in more depth.
Many of these lines are commented out with the hash symbol #; they are there to show you some commonly needed gems and to give examples of the Bundler syntax. For now, we won't need any gems other than the defaults.
Unless you specify a version number to the gem command, Bundler will automatically install the latest version of the gem. Unfortunately, gem updates often cause minor but potentially confusing breakage, so in this tutorial we'll include explicit version numbers known to work, as seen in Listing 1.5 (which also omits the commented-out lines from Listing 1.4).
Listing 1.5 adds the lines
identifying the version of Ruby expected by the application (especially useful when deploying applications ( Section 1.4)), along with the RVM gemset ( Section 1.2.2.3). Because the gemset line starts with #, which is the Ruby comment character, it will be ignored if you aren't using RVM, but if you are RVM will conveniently use the right Ruby version/gemset combination upon entering the application directory. (If you are using a version of Ruby other than 2.0.0, you should change the Ruby version line accordingly.)
The updated Gemfile also changes the line for jQuery, the default JavaScript library used by Rails, from
to
We've also changed
to
which forces Bundler to install version 1.3.8 of the sqlite3 gem. Note that we've also taken this opportunity to arrange for the gem to be included only in a development environment ( Section 7.1.1), which prevents potential conflicts with the database used by Heroku ( Section 1.4).
Listing 1.5 also changes a few other lines, converting
to
The syntax
installs the latest version of the uglifier gem (which handles file compression for the asset pipeline) as long as it's greater than or equal to version 1.3.0-even if it's, say, version 7.2. Meanwhile, the code
installs the gem coffee-rails (also needed by the asset pipeline) as long as it's newer than version 4.0.0 but not newer than 4.1. In other words, the >= notation always installs the latest gem when you run bundle install, whereas the ~> 4.0.0 notation only installs updated gems representing minor point releases (e.g., from 4.0.0 to 4.0.1), but not major point releases (e.g., from 4.0 to 4.1). Unfortunately, experience shows that even minor point releases can break things, so for the Rails Tutorial we'll err on the side of caution by including exact version numbers for virtually all gems. You are welcome to use the most up-to-date version of any gem, including using the~> construction in the Gemfile (which I generally recommend for more advanced users), but be warned that this may cause the tutorial to act unpredictably.
Once you've assembled the proper Gemfile, install the gems using bundle update and bundle install:
The bundle install command might take a few moments, but when it's done our application will be ready to run.
Thanks to running rails new in Section 1.2.3 and bundle install in Section 1.2.4, we already have an application we can run-but how? Happily, Rails comes with a command-line program, or script, that runs a local web server, visible only from your development machine:
(If your system complains about the lack of a JavaScript runtime, visit the execjs page at GitHub for a list of possibilities. I particularly recommend installing Node.js.) This tells us that the application is running on port number 3000 at the address 0.0.0.0. This address tells the computer to listen on every available IP address configured on that specific machine; in particular, we can view the application using the special address 127.0.0.1, which is also known as localhost. We can see the result of visiting http://localhost:3000/ in Figure 1.3.
To see information about our first application, click on the link "About your application's environment". The result is shown in Figure 1.4. ( Figure 1.4 represents the environment on my machine when I made the screenshot; your results may differ.)
Of course, we don't need the default Rails page in the long run, but it's nice to see it working for now. We'll remove the default page (and replace it with a custom home page) in Section 5.3.2.
Even at this early stage, it's helpful to get a high-level overview of how Rails applications work ( Figure 1.5). You might have noticed that the standard Rails application structure ( Figure 1.2) has an application directory called app/ with three subdirectories: models, views, and controllers. This is a hint that Rails follows the model-view-controller (MVC) architectural pattern, which enforces a separation between "domain logic" (also called "business logic") from the input and presentation logic associated with a graphical user interface (GUI). In the case of web applications, the "domain logic" typically consists of data models for things like users, articles, and products, and the GUI is just a web page in a web browser.
When interacting with a Rails application, a browser sends a request, which is received by a web server and passed on to a Rails controller, which is in charge of what to do next. In some cases, the controller will immediately render a view, which is a template that gets converted to HTML and sent back to the browser. More commonly for dynamic sites, the controller interacts with a model, which is a Ruby object that represents an element of the site (such as a user) and is in charge of communicating with the database. After invoking the model, the controller then renders the view and returns the complete web page to the browser as HTML.

If this discussion seems a bit abstract right now, worry not; we'll refer back to this section frequently. In addition, Section 2.2.2 has a more detailed discussion of MVC in the context of the demo app. Finally, the sample app will use all aspects of MVC; we'll cover controllers and views starting in Section 3.1, models starting in Section 6.1, and we'll see all three working together in Section 7.1.2.
Now that we have a fresh and working Rails application, we'll take a moment for a step that, while technically optional, would be viewed by many Rails developers as practically essential, namely, placing our application source code under version control. Version control systems allow us to track changes to our project's code, collaborate more easily, and roll back any inadvertent errors (such as accidentally deleting files). Knowing how to use a version control system is a required skill for every software developer.
There are many options for version control, but the Rails community has largely standardized on Git, a distributed version control system originally developed by Linus Torvalds to host the Linux kernel. Git is a large subject, and we'll only be scratching the surface in this book, but there are many good free resources online; I especially recommend by Scott Chacon (Apress, 2009). Putting your source code under version control with Git is strongly recommended, not only because it's nearly a universal practice in the Rails world, but also because it will allow you to share your code more easily ( Section 1.3.4) and deploy your application right here in the first chapter ( Section 1.4).
The first step is to install Git if you haven't yet followed the steps in Section 1.2.2.2. (As noted in that section, this involves following the instructions in the Installing Git section of Pro Git.)
After installing Git, you should perform a set of one-time setup steps. These are system setups, meaning you only have to do them once per computer:
I also like to use co in place of the more verbose checkout command, which we can arrange as follows:
This tutorial will usually use the full checkout command, which works for systems that don't have co configured, but in real life I nearly always use git co.
As a final setup step, you can optionally set the editor Git will use for commit messages. If you use a graphical editor such as Sublime Text, TextMate, gVim, or MacVim, you need to use a flag to make sure that the editor stays attached to the shell instead of detaching immediately:
Replace "subl -w" with "mate -w" for TextMate, "gvim -f" for gVim, or "mvim -f" for MacVim.
Now we come to some steps that are necessary each time you create a new repository. First navigate to the root directory of the first app and initialize a new repository:
The next step is to add the project files to the repository. There's a minor complication, though: by default Git tracks the changes of all the files, but there are some files we don't want to track. For example, Rails creates log files to record the behavior of the application; these files change frequently, and we don't want our version control system to have to update them constantly. Git has a simple mechanism to ignore such files: simply include a file called .gitignore in the application root directory with some rules telling Git which files to ignore.
Looking again at Table 1.1, we see that the rails command creates a default .gitignore file in the application root directory, as shown in Listing 1.6.
Listing 1.6 causes Git to ignore files such as log files, Rails temporary ( tmp) files, and SQLite databases. (For example, to ignore log files, which live in the log/ directory, we use log/*.log to ignore all files that end in .log.) Most of these ignored files change frequently and automatically, so including them under version control is unnecessary. Moreover, when collaborating with others, these irrelevant changes can cause frustrating conflicts.
The .gitignore file in Listing 1.6 is a good start, but for convenience and security ( Listing 3.2) I recommend using Listing 1.7 instead. This augmented .gitignore arranges to ignore Rails documentation files, Vim and Emacs swap files, and (for OS X users) the weird .DS_Store directories created by the Mac Finder application. If you want to use this broader set of ignored files, open up .gitignore in your favorite text editor and fill it with the contents of Listing 1.7.
An augmented .gitignore file.
Finally, we'll add the files in your new Rails project to Git and then commit the results. You can add all the files (apart from those that match the ignore patterns in .gitignore) as follows:
Here the dot '.' represents the current directory, and Git is smart enough to add the files recursively, so it automatically includes all the subdirectories. This command adds the project files to a staging area, which contains pending changes to your project; you can see which files are in the staging area using the status command:
(The results are long, so I've used vertical dots to indicate omitted output.)
To tell Git you want to keep the changes, use the commit command:
$ git commit -m "Initialize repository" [master (root-commit) df0a62f] Initialize repository 42 files changed, 8461 insertions(+), 0 deletions(-) create mode 100644 README.rdoc create mode 100644 Rakefile . . .
The -m flag lets you add a message for the commit; if you omit -m, Git will open the editor you set in Section 1.3.1 and have you enter the message there.
It is important to note that Git commits are local, recorded only on the machine on which the commits occur. This is in contrast to the popular open-source version control system called Subversion, in which a commit necessarily makes changes on a remote repository. Git divides a Subversion-style commit into its two logical pieces: a local recording of the changes ( git commit) and a push of the changes up to a remote repository ( git push). We'll see an example of the push step in Section 1.3.5.
By the way, you can see a list of your commit messages using the log command:
To exit git log, you may have to type q to quit.
It's probably not entirely clear at this point why putting your source under version control does you any good, so let me give just one example. (We'll see many others in the chapters ahead.) Suppose you've made some accidental changes, such as (D'oh!) deleting the critical app/controllers/ directory:
Here we're using the Unix ls command to list the contents of the app/controllers/ directory and the rm command to remove it. The -rf flag means "recursive force", which recursively removes all files, directories, subdirectories, and so on, without asking for explicit confirmation of each deletion.
Let's check the status to see what's up:
We see here that a file has been deleted, but the changes are only on the "working tree"; they haven't been committed yet. This means we can still undo the changes easily by having Git check out the previous commit with the checkout command (and a -f flag to force overwriting the current changes):
The missing directory and file are back. That's a relief!
Now that you've put your project under version control with Git, it's time to push your code up to GitHub, a social coding site optimized for hosting and sharing Git repositories. Putting a copy of your Git repository at GitHub serves two purposes: it's a full backup of your code (including the full history of commits), and it makes any future collaboration much easier. This step is optional, but being a GitHub member will open the door to participating in a wide variety of open-source projects.
GitHub has a variety of paid plans, but for open-source code their services are free, so sign up for a free GitHub account if you don't have one already. (You might have to follow the GitHub tutorial on creating SSH keys first.) After signing up, click on the link to create a repository and fill in the information as in Figure 1.6. (Take care not to initialize the repository with a README file, as rails new creates one of those automatically.) After submitting the form, push up your first application as follows:
These commands tell Git that you want to add GitHub as the origin for your main ( master) branch and then push your repository up to GitHub. (Don't worry about what the -u flag does; if you're curious, do a web search for "git set upstream".) Of course, you should replace <username> with your actual username. For example, the command I ran was
The result is a page at GitHub for the first application repository, with file browsing, full commit history, and lots of other goodies ( Figure 1.7).
GitHub also has native applications to augment the command-line interface, so if you're more comfortable with GUI apps you might want to check out GitHub for Windows or GitHub for Mac. (GitHub for Linux is still just Git, it seems.)
If you've followed the steps in Section 1.3.4, you might notice that GitHub automatically shows the contents of the README file on the main repository page. In our case, since the project is a Rails application generated using the rails command, the README file is the one that comes with Rails ( Figure 1.8). Because of the .rdoc extension on the file, GitHub ensures that it is formatted nicely, but the contents aren't helpful at all, so in this section we'll make our first edit by changing the README to describe our project rather than the Rails framework itself. In the process, we'll see a first example of the branch, edit, commit, merge workflow that I recommend using with Git.

Git is incredibly good at making branches, which are effectively copies of a repository where we can make (possibly experimental) changes without modifying the parent files. In most cases, the parent repository is the master branch, and we can create a new topic branch by using checkout with the -b flag:
Here the second command, git branch, just lists all the local branches, and the asterisk * identifies which branch we're currently on. Note that git checkout -b modify-README both creates a new branch and switches to it, as indicated by the asterisk in front of the modify-README branch. (If you set up the co alias in Section 1.3, you can use git co -b modify-README instead.)
The full value of branching only becomes clear when working on a project with multiple developers, but branches are helpful even for a single-developer tutorial such as this one. In particular, the master branch is insulated from any changes we make to the topic branch, so even if we really screw things up we can always abandon the changes by checking out the master branch and deleting the topic branch. We'll see how to do this at the end of the section.
By the way, for a change as small as this one I wouldn't normally bother with a new branch, but it's never too early to start practicing good habits.
After creating the topic branch, we'll edit it to make it a little more descriptive. I prefer the Markdown markup language to the default RDoc for this purpose, and if you use the file extension .md then GitHub will automatically format it nicely for you. So, first we'll use Git's version of the Unix mv ("move") command to change the name, and then fill it in with the contents of Listing 1.8:
With the changes made, we can take a look at the status of our branch:
At this point, we could use git add . as in Section 1.3.2, but Git provides the -a flag as a shortcut for the (very common) case of committing all modifications to existing files (or files created using git mv, which don't count as new files to Git):
Be careful about using the -a flag improperly; if you have added any new files to the project since the last commit, you still have to tell Git about them using git add first.
Note that we write the commit message in the present tense. Git models commits as a series of patches, and in this context it makes sense to describe what each commit does, rather than what it did. Moreover, this usage matches up with the commit messages generated by Git commands themselves. See the GitHub post Shiny new commit styles for more information.
Now that we've finished making our changes, we're ready to merge the results back into our master branch:
$ git checkout master Switched to branch 'master' $ git merge modify-README Updating 34f06b7..2c92bef Fast forward README.rdoc | 243 -------------------------------------------------- README.md | 5 + 2 files changed, 5 insertions(+), 243 deletions(-) delete mode 100644 README.rdoc create mode 100644 README.md
Note that the Git output frequently includes things like 34f06b7, which are related to Git's internal representation of repositories. Your exact results will differ in these details, but otherwise should essentially match the output shown above.
After you've merged in the changes, you can tidy up your branches by deleting the topic branch using git branch -d if you're done with it:
This step is optional, and in fact it's quite common to leave the topic branch intact. This way you can switch back and forth between the topic and master branches, merging in changes every time you reach a natural stopping point.
As mentioned above, it's also possible to abandon your topic branch changes, in this case with git branch -D:
# For illustration only; don't do this unless you mess up a branch $ git checkout -b topic-branch $ <really screw up the branch> $ git add . $ git commit -a -m "Major screw up" $ git checkout master $ git branch -D topic-branch
Unlike the -d flag, the -D flag will delete the branch even though we haven't merged in the changes.
Now that we've updated the README, we can push the changes up to GitHub to see the result. Since we have already done one push ( Section 1.3.4), on most systems we can omit origin master, and simply run git push:
As promised, GitHub nicely formats the new file using Markdown ( Figure 1.9).

Even at this early stage, we're already going to deploy our (still-empty) Rails application to production. This step is optional, but deploying early and often allows us to catch any deployment problems early in our development cycle. The alternative-deploying only after laborious effort sealed away in a development environment-often leads to terrible integration headaches when launch time comes.
Deploying Rails applications used to be a pain, but the Rails deployment ecosystem has matured rapidly in the past few years, and now there are several great options. These include shared hosts or virtual private servers running Phusion Passenger (a module for the Apache and Nginx web servers), full-service deployment companies such as Engine Yard and Rails Machine, and cloud deployment services such as Engine Yard Cloud and Heroku.
My favorite Rails deployment option is Heroku, which is a hosted platform built specifically for deploying Rails and other web applications. Heroku makes deploying Rails applications ridiculously easy-as long as your source code is under version control with Git. (This is yet another reason to follow the Git setup steps in Section 1.3 if you haven't already.) The rest of this section is dedicated to deploying our first application to Heroku.
Heroku uses the PostgreSQL database (pronounced "post-gres-cue-ell", and often called "Postgres" for short), which means that we need to add the pg gem in the production environment to allow Rails to talk to Postgres:
Note also the addition of the rails_12factor gem, which is used by Heroku to serve static assets such as images and stylesheets.
As mentioned in Section 1.2.4, it's also a good idea to specify explictly which version of Ruby our applications expects:
(Here I've also added the optional RVM gemset line for convenience. You should substitute '1.9.3' if that's the version of Ruby you're using, though for this tutorial the difference shouldn't ever matter.) Applying these changes to the Gemfile from Listing 1.5 yields Listing 1.9.
To install it, we run bundle install with a special flag:
The --without production option prevents the local installation of any production gems, which in this case consists of pg and rails_12factor. (If Bundler complains about a readline error, try adding gem 'rb-read\-line', '~> 0.4.2' to your Gemfile.) Because the only gems we've added are restricted to a production environment, right now this command doesn't actually install any additional local gems, but it's needed to update Gemfile.lock with the pg and rails_12factor gems and the specific Ruby version. We can commit the resulting change as follows:
(Some readers have reported that they need one last bit of configuration at this point, namely, creating the files Heroku needs to serve static assets like images and CSS:
(This uses the rake command, which we'll cover in more detail in Section 2.2.) The asset precompile step shouldn't be necessary, and I have been unable to reproduce the issue, but the reports are common enough that I include it here for reference.)
Next we have to create and configure a new Heroku account. The first step is to sign up for Heroku; after checking your email to complete the creation of your account, install the necessary Heroku software using the Heroku Toolbelt. Then use the heroku command to log in at the command line (you may have to exit and restart your terminal program first):
Finally, navigate back to your Rails project directory and use the heroku command to create a place on the Heroku servers for the sample app to live ( Listing 1.10).
The heroku command creates a new subdomain just for our application, available for immediate viewing. There's nothing there yet, though, so let's get busy deploying.
To deploy the application, the first step is to use Git to push it up to Heroku:
There is no step two! We're already done ( Figure 1.10). To see your newly deployed application, you can visit the address that you saw when you ran heroku create (i.e., Listing 1.10, but with the address for your app, not the address for mine). You can also use an argument to the heroku command that automatically opens your browser with the right address:
Unfortunately, the resulting page is an error; as of Rails 4.0, for technical reasons the default Rails page doesn't work on Heroku. The good news is that the error will go away (in the context of the full sample application) when we add a root route in Section 5.3.2.
Once you've deployed successfully, Heroku provides a beautiful interface for administering and configuring your application ( Figure 1.11).
There are many Heroku commands, and we'll barely scratch the surface in this book. Let's take a minute to show just one of them by renaming the application as follows:
Don't use this name yourself; it's already taken by me! In fact, you probably shouldn't bother with this step right now; using the default address supplied by Heroku is fine. But if you do want to rename your application, you can arrange for it to be reasonably secure by using a random or obscure subdomain, such as the following:
hwpcbmze.herokuapp.com seyjhflo.herokuapp.com jhyicevg.herokuapp.com
With a random subdomain like this, someone could visit your site only if you gave them the address. (By the way, as a preview of Ruby's compact awesomeness, here's the code I used to generate the random subdomains:
Pretty sweet.)
In addition to supporting subdomains, Heroku also supports custom domains. (In fact, the Ruby on Rails Tutorial site lives at Heroku; if you're reading this book online, you're looking at a Heroku-hosted site right now!) See the Heroku documentation for more information about custom domains and other Heroku topics.
We've come a long way in this chapter: installation, development environment setup, version control, and deployment. If you want to share your progress at this point, feel free to send a tweet or Facebook status update with something like this:
All that's left is to actually start learning Rails! Let's get to it.
Start Here
Everything you need to know to install Rails and create your first application.
Models
This guide will get you started with models, persistence to database and the Active Record pattern and library.
This guide covers how you can use Active Record migrations to alter your database in a structured and organized manner.
This guide covers how you can use Active Record validations
This guide covers how you can use Active Record callbacks.
This guide covers all the associations provided by Active Record.
This guide covers the database query interface provided by Active Record.
Views
This guide provides an introduction to Action View and introduces a few of the more common view helpers.
This guide covers the basic layout features of Action Controller and Action View, including rendering and redirecting, using content_for blocks, and working with partials.
Guide to using built-in Form helpers.
Controllers
This guide covers how controllers work and how they fit into the request cycle in your application. It includes sessions, filters, and cookies, data streaming, and dealing with exceptions raised by a request, among other topics.
This guide covers the user-facing features of Rails routing. If you want to understand how to use routing in your own Rails applications, start here.
Digging Deeper
This guide documents the Ruby core extensions defined in Active Support.
This guide covers how to add internationalization to your applications. Your application will be able to translate content to different languages, change pluralization rules, use correct date formats for each country and so on.
This guide describes how to use Action Mailer to send and receive emails.
This is a rather comprehensive guide to doing both unit and functional tests in Rails. It covers everything from 'What is a test?' to the testing APIs. Enjoy.
This guide describes common security problems in web applications and how to avoid them with Rails.
This guide describes how to debug Rails applications. It covers the different ways of achieving this and how to understand what is happening "behind the scenes" of your code.
This guide covers the basic configuration settings for a Rails application.
This guide covers the command line tools and rake tasks provided by Rails.
Various caching techniques provided by Rails.
This guide documents the asset pipeline.
This guide covers the built-in Ajax/JavaScript functionality of Rails.
This guide explains how to write a mountable engine.
This guide explains the internals of the Rails initialization process as of Rails 3.1
Extending Rails
This guide covers how to build a plugin to extend the functionality of Rails.
This guide covers Rails integration with Rack and interfacing with other Rack components.
This guide covers the process of adding a brand new generator to your extension or providing an alternative to an element of a built-in Rails generator (such as providing alternative test stubs for the scaffold generator).
Contributing to Ruby on Rails
Rails is not 'somebody else's framework.' This guide covers a variety of ways that you can get involved in the ongoing development of Rails.
This guide documents the Ruby on Rails API documentation guidelines.
This guide documents the Ruby on Rails guides guidelines.
Maintenance Policy
What versions of Ruby on Rails are currently supported, and when to expect new versions.
Release Notes
This guide helps in upgrading applications to latest Ruby on Rails versions.
Release notes for Rails 4.0.
Release notes for Rails 3.2.
Release notes for Rails 3.1.
Release notes for Rails 3.0.
Release notes for Rails 2.3.
Release notes for Rails 2.2.
Feedback
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our documentation contributions section.
You may also find incomplete content, or stuff that is not up to date. Please do add any missing documentation for master. Make sure to check Edge Guides first to verify if the issues are already fixed or not on the master branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please open an issue.
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome in the rubyonrails-docs mailing list.


Accelerating Your Learning
 If you have no prior development experience, one of the worst things you can do when learning Rails is to just dive in. Some of the concepts build on each other, so jumping in would be like signing up for a calculus class before you've learned algebra. Sure, you could muddle through it, but most of your time would be spent trying to figure out why things aren't working.
If you have no prior development experience, one of the worst things you can do when learning Rails is to just dive in. Some of the concepts build on each other, so jumping in would be like signing up for a calculus class before you've learned algebra. Sure, you could muddle through it, but most of your time would be spent trying to figure out why things aren't working.
Another difficulty for a beginner is figuring out what to learn. SQL, XHTML, CSS, XSS, RDF, RDBMS-what should you drink from the fire hose of acronyms? Which topics are worthwhile for a beginner to learn and which are better left for later?
Another mistake is spending too much time mastering a concept when you only need a basic understanding.
Therefore, to accelerate your learning, learn the right things in the right order at the right depth.The following roadmap will help you do exactly that.
But First Some Ground Rules...
It takes a significant investment of time to learn Rails. It will be months or even years before you are a productive Rails programmer. So don't make the mistake of choosing Rails when you should be learning something else! Before committing to Rails, you should:
- know the difference between a web site and a web application
- know the difference between a CMS and a web application
- know the difference between a programming language and a web framework
- know that Rails is a web framework (not a CMS, not a programming language) that helps you create web applications
Otherwise, you will waste your time learning Rails when all you really needed was WordPress.
Update: In addition to this roadmap, you should also check out the very nice screencast Getting Started with Rails.
Roadmap for Learning Rails
Here is a roadmap specially designed for a beginner to navigate their way to Rails mastery. Blue boxes represent technologies and green boxes represent intermediate goals. Arrows represent learning dependencies. Below the roadmap I've listed more information about learning each technology.
I've intentionally structured this roadmap so that you can learn one thing at a time. That way, you'll spend more time creating and less time confused.

Ruby is the most important technology to know when learning Rails. Take the time to get comfortable with Ruby. If you have never programmed before, this will take a while. Avoid the temptation to skip ahead without Ruby competence. You will pay for it in the purgatory of awful debugging sessions.
Make sure you fully understand object-oriented programming and that the language constructs are second nature to you. Given a programming problem, you should be able to generate several different solutions and explain the strengths and weaknesses of each. You should know how DSLs work. You don't need to be an expert in Ruby, but you shouldn't be struggling with basic concepts like each, modules and symbols.
There is no such thing as a good Rails programmer who is not a good Ruby programmer. Your Rails skills can only be as good as your Ruby skills.
try ruby! is a fun way to jump right into Ruby right now.
The Ruby Programming Language is a great in-depth guide. (By the way, the best programming books are from O'Reilly and The Pragmatic Programmers.)
HTML is a text markup language, not a programming language, which makes it much easier to learn than Ruby. Start by learning HTML 4 and save HTML 5 for later.
Now that you know HTML, use CSS to give it some style. Your goal should be to understand the basics. You should know how to add styles to your web page and understand the box model. After you understand the basics, move on. Lack of CSS knowledge won't get in the way of learning other concepts.
Use Firefox as your development browser and installFirebug, which is a great tool for debugging HTML and CSS in the browser.
Web Developer is another great Firefox add-on that you should install.
Since your goal is to become a web programmer, you should put something on the web. First, you need to know HTML (and optionally CSS to make it pretty). Then you need to find a web host to host your web page. You can usually find one for free or a few bucks a month. Then you need to buy a domain name from a registrar such as Namecheap. Finally, you need to understand just enough about the Domain Name System (DNS) to point your domain name at your web host. (By the way, registrars often provide hosting as well.)
You really don't need to put something on the web to learn Rails. However, I think it's a great idea to get something on the web as soon as you can so that you gain the experience that can only come from managing real web sites. You can start small. For example, I launched the world's smallest web site at instantzendo.com. Publishing something on the web is a great morale booster, too, so do it as soon as you can.
You may notice that JavaScript is shown as a learning dependency for nanoc. This is not quite accurate; you don't need to know JavaScript to learn nanoc. The reason that JavaScript is shown here in the roadmap is that after you've gotten comfortable with HTML and CSS, that's a good time to explore JavaScript.
Your goal should be to learn just the basics. Learn how to load JavaScript files into your web page and how to insert JavaScript directly into your HTML. Learn how you can manipulate the DOM with JavaScript. Learn just enough about JavaScript so that you know what it is and how to use JavaScript that other people have written. That's all you need to know for now. Later, when you are learning Rails, JavaScript will come up now and then but you won't need to write any yourself to learn the basics of Rails.
By now you should be competent in Ruby as well as HTML. nanoc combines these by using Ruby as a tool to help you write static web pages.
nanoc is in no way related to Rails, so you can get away with not knowing it. However, it's a great next step in the roadmap since it combines Ruby and HTML without adding a lot of additional concepts. It's also a great tool to have in your toolbox. I use it myself.
The main Rails-related concept you'll learn here is how to embed Ruby inside of HTML.
With Rack, you are officially leaving the world of web sites and entering the world of web apps. No longer are you sending static HTML files to the browser; you are programmatically building HTML on-the-fly to send to the browser.
Rack is a great foundational concept. It forces you to understand HTTP, which is required if you are going to be a good Rails developer. Rack is also the technology that every modern Ruby web framework and web server uses, so time spent learning Rack is time well-spent.
Note that you don't need to know nanoc to learn Rack; Rack is simply a good next step after you know nanoc.
Git has no learning dependencies, so you can learn it whenever you want. But you need to know it before you use Heroku.
Git is a version control system so it basically helps you keep track of changes to your files. Don't underestimate the learning curve of Git. There are a lot of concepts to learn and some of the commands are counter-intuitive. Take the time to understand Git well; it will pay off later. But don't bother learning everything about Git. Learn what you need to know to manage a typical Git workflow. Note that if you are working by yourself, your workflow will be different than those working in teams.
GitHub is the home for the Ruby community's open-source projects.
Heroku is your friend. They are saving you the trouble of learning how to administer a Linux web server. And they are helping you for free. You should give them a hug.
Now that you know Rack and Git, you are dangerous. Write a Rack app, put it in a Git repository, then push this Git repo to Heroku and they will put it on the web for you. You will have published your first web app. Welcome to the club, fellow web programmer!
Because you haven't learned about databases yet, you will be limited in the kinds of Rack apps you can create. However, you can still write a useful Rack app without a database. My 2rgb.com Rack app (which is hosted on Heroku) is simply a Ruby method wrapped up as a web app. If you're curious, here's the source code.
Heroku is not just good for learning and for Rack apps, it's also good for production Rails apps.
Almost all web apps are backed by a database and most of these databases are RDBMSs that understand SQL. Take the time to learn the basics of SQL: what a relation is, SELECT statements, etc. But don't get too deep-Rails hides the SQL from you so you don't need to know much in order to learn Rails. However, you should become more familiar with SQL later in order to write professional web apps.
You may hear a lot of discussion about NoSQL. Save that for later after you're comfortable with Rails, since most Rails apps still use RDBMSs.
Sinatra is a simple Ruby web framework that is much easier to learn than Rails. The first thing to do is convert a Rack app you wrote into a Sinatra app. Then create a database and use ActiveRecord to interact with your database from within Sinatra.
You don't need to know Sinatra to know Rails. However, it makes it easier to learn Rails since it introduces you to web frameworks without the complexity of Rails. Sinatra is also a nice web framework to know and later on you may prefer Sinatra to Rails for some projects.
It is common to feel disoriented when learning Rails. The framework does so much for you and there is so much magic that it's hard to understand the flow of control and how the different parts of the framework relate. However, if you've followed this roadmap, this shouldn't happen to you.
Agile Web Development with Rails is a popular Rails tutorial book.
RailsCasts are an excellent way to learn about various Rails topics.
Five More Tips to Accelerate Your Rails Education
You can skip to the end and leave a response. Pinging is currently not allowed.


Sinatra Core
Many people love the simplicity and expressiveness of Sinatra but quickly find themselves missing a great deal of functionality provided by other web frameworks such as Rails when building non-trivial applications.
Sinatra acts as a thin layer on top of Rack itself and the "micro"-framework is kept light introducing complexities only when required by the particular application. Our goal with Padrino is to stay true to the core principles of Sinatra including a focus on simplicity and modularity.
Starting from this assumption, we have developed a different approach to a web development framework. We expand on Sinatra through the addition of standard libraries including helpers, components, and other functionality that are needed in a framework suitable for arbitrarily complex web applications.
Drop-in Admin
Padrino ships with an Admin Interface that includes the following features:
Orm Agnostic
Adapters for datamapper, activerecord, sequel, mongomapper, mongoid
Authentication
Account authentication support and permission management
Template Agnostic
View support for Erb and Haml rendering engines
Scaffold
Create a model "admin interface" by invoking a command
MultiLanguage
Translated into 10 languages including English, Spanish, and Italian
Example:
$ padrino-gen project cool --orm activerecord $ cd cool $ padrino-gen admin $ padrino-gen admin_page post
For usage information, check out our detailed admin guide.
Lightweight
The Padrino code base has been kept simple and easy to understand, maintain and enhance. The generator for each new project creates a clean and compact directory structure keeping your code simple and well organized.
Padrino strives to adhere to the following basic principles:
This framework can be used with ease for web development for a project of any size from your lightweight json web service to a large full-stack web application!
Agnostic
Padrino is orm, javascript, testing, rendering, mocking agnostic supporting the use of any number of available libraries.
The available components and their defaults are listed below:
Just create the project with the usual generator command and pass in your preferred components!
$ padrino g project cool --orm mongomapper $ padrino g project cool --renderer haml --stylesheet sass $ padrino g project cool --script mootools $ padrino g project cool --orm mongoid --script mootools $ padrino g project -h # shows available options
Comprehensive
Building on our experience in developing web applications, we designed a framework that meets all the requirements for creating a top notch web application in a clean, concise and simple environment, with minimal deadline delays.
We provide you with the following out of the box:
Logging:
Provides a unified logger that can interact with your ORM or any library of your choice.

Padrino Admin is an easy way to manage your data!
Preface
Padrino is a ruby framework built upon the Sinatra web library. Sinatra is a DSL for creating simple web applications in Ruby. Padrino was created to make it fun and easy to code more advanced web applications while still adhering to the spirit that makes Sinatra great!
Introduction
Many people love the simplicity and expressiveness of Sinatra but quickly come to miss a great deal of functionality provided by other web frameworks such as Rails when building non-trivial applications.
Our goal with Padrino is to stay true to the core principles of Sinatra while at the same time creating a standard library of tools, helpers and functions that will make Sinatra suitable for increasingly complex applications.


There's no shortage of Node.js tutorials out there, but most of them cover specific use cases or topics that only apply when you've already got Node up and running. I see comments every once and awhile that sound something like, "I've downloaded Node, now what?" This tutorial answers that question and explains how to get started from the very beginning.
What is Node.js?
A lot of the confusion for newcomers to Node is misunderstanding exactly what it is. The description on nodejs.org definitely doesn't help.
An important thing to realize is that Node is not a webserver. By itself it doesn't do anything. It doesn't work like Apache. There is no config file where you point it to you HTML files. If you want it to be a HTTP server, you have to write an HTTP server (with the help of its built-in libraries). Node.js is just another way to execute code on your computer. It is simply a JavaScript runtime.
Installing Node
Node.js is very easy to install. If you're using Windows or Mac, installers are available on the download page.
I've Installed Node, now what?
Once installed you'll have access to a new command called "node". You can use the node command in two different ways. The first is with no arguments. This will open an interactive shell (REPL: read-eval-print-loop) where you can execute raw JavaScript code.
$ node
> console.log('Hello World');
Hello World
undefined

In the above example I typed "console.log('Hello World')" into the shell and hit enter. Node will then execute that code and we can see our logged message. It also prints "undefined" because it displays the return value of each command and console.log doesn't return anything.
The other way to run Node is by providing it a JavaScript file to execute. This is almost always how you'll be using it.
hello.js
console.log('Hello World');$ node hello.js Hello World

In this example, I moved the console.log message into a file then passed that file to the node command as an argument. Node then runs the JavaScript in that file and prints "Hello World".
Doing Something Useful - File I/O
Running plain JavaScript is fun and all, but not very useful. This is why Node.js also includes a powerful set of libraries (modules) for doing real things. In this first example I'm going to open a log file and parse it.
example_log.txt
2013-08-09T13:50:33.166Z A 2 2013-08-09T13:51:33.166Z B 1 2013-08-09T13:52:33.166Z C 6 2013-08-09T13:53:33.166Z B 8 2013-08-09T13:54:33.166Z B 5
What this log data means is not important, but basically each message contains a date, a letter, and a value. I want to add up the values for each letter.
The first thing we need to do it read the contents of the file.
my_parser.js
// Load the fs (filesystem) module var fs = require('fs'); // Read the contents of the file into memory. fs.readFile('example_log.txt', function (err, logData) { // If an error occurred, throwing it will // display the exception and end our app. if (err) throw err; // logData is a Buffer, convert to string. var text = logData.toString(); });Fortunately Node.js makes file I/O really easy with the built-in filesystem (fs) module. The fs module has a function named readFile that takes a file path and a callback. The callback will be invoked when the file is done being read. The file data comes in the form of a Buffer, which is basically a byte array. We can convert it to a string using the toString() function.
Now let's add in the parsing. This is pretty much normal JavaScript so I won't go into any details.
my_parser.js
// Load the fs (filesystem) module. var fs = require('fs'); // Read the contents of the file into memory. fs.readFile('example_log.txt', function (err, logData) { // If an error occurred, throwing it will // display the exception and kill our app. if (err) throw err; // logData is a Buffer, convert to string. var text = logData.toString(); var results = {}; // Break up the file into lines. var lines = text.split('\n'); lines.forEach(function(line) { var parts = line.split(' '); var letter = parts[1]; var count = parseInt(parts[2]); if(!results[letter]) { results[letter] = 0; } results[letter] += parseInt(count); }); console.log(results); // { A: 2, B: 14, C: 6 } });Now when you pass this file as the argument to the node command it will print the result and exit.
$ node my_parser.js
{ A: 2, B: 14, C: 6 }

I use Node.js a lot for scripting like this. It's much easier and a more powerful alternative to bash scripts.
Asynchronous Callbacks
As you saw in the previous example, the typical pattern in Node.js is to use asynchronous callbacks. Basically you're telling it to do something and when it's done it will call your function (callback). This is because Node is single-threaded. While you're waiting on the callback to fire, Node can go off and do other things instead of blocking until the request is finished.
This is especially important for web servers. It's pretty common in modern web applications to access a databases. While you're waiting for the database to return results Node can process more requests. This allows you to handle thousands of concurrent connections with very little overhead, compared to creating a separate thread for each connection.
Doing Something Useful - HTTP Server
Like I said before Node doesn't do anything out of the box. One of the built-in modules makes it pretty easy to create a basic HTTP server, which is the example on the Node.js homepage.
my_web_server.js
var http = require('http'); http.createServer(function (req, res) { res.writeHead(200, {'Content-Type': 'text/plain'}); res.end('Hello World\n'); }).listen(8080); console.log('Server running on port 8080.');When I say basic, I mean basic. This is not a full-featured HTTP server. It can't serve any HTML file or images. In fact, no matter what you request, it will return 'Hello World'. However, you can run this and hit http://localhost:8080 in your browser and you'll see the text.
$ node my_web_server.js
You might notice something a little different now. Your Node.js application no longer exits. This is because you created a server and your Node.js application will continue to run and respond to requests until you kill it yourself.
If you want this to be a full-featured web server, then you have to do that work. You have to check what was requested, read the appropriate files, and send the content back. There's good news, though. People have already done this hard work for you.
Doing Something Useful - Express
Express is a framework that makes creating most normal websites very simple. The first thing you have to do it install it. Along with the node command you also have access to a command called "npm". This tool gives you access to an enormous collection of modules created by the community, and one of them is Express.
$ cd /my/app/location $ npm install express
When you install a module, it will put it in a node_modules folder inside your application directory. You can now require it like any built-in module. Let's create a basic static file server using Express.
my_static_file_server.js
var express = require('express'), app = express(); app.use(express.static(__dirname + '/public')); app.listen(8080);$ node my_static_file_server.js
You now have a pretty capable static file server. Anything you put in the /public folder can now be requested by your browser and displayed. HTML, images, almost anything. So for example, if you put an image called "my_image.png" inside the public folder, you can access it using your browser by going to http://localhost:8080/my_image.png. Of course Express has many many more features, but you can look those up as you continue developing.
{kind=link}
NPM
We touched on npm a little in the previous section, but I want to emphasize how important this tool will be to normal Node.js development. There are thousands of modules available that solve almost all typical problems that you're likely to encounter. Remember to check npm before re-inventing the wheel. It's not unheard of for a typical Node.js application to have dozens of dependencies.
In the previous example we manually installed Express. If you have a lot of dependencies, that's not going to be a very good way to install them. That's why npm makes use of a package.json file.
package.json
{
"name" : "MyStaticServer",
"version" : "0.0.1",
"dependencies" : {
"express" : "3.3.x"
}
}
A package.json file contains an overview of your application. There are a lot of available fields, but this is pretty much the minimum. The dependencies section describes the name and version of the modules you'd like to install. In this case I'll accept any version of Express 3.3. You can list as many dependencies as you want in this section.
Now instead of installing each dependency separately, we can run a single command and install all of them.
$ npm install
When you run this command npm will look in the current folder for a package.json file. If it finds one, it will install every dependency listed.
Code Organization
So far we've only been using a single file, which isn't very maintainable. In most applications your code will be split into several files. There's no standard or enforced organization to what files go where. This isn't Rails. There's no concept of views go here and controllers go there. You can do whatever you want.
Let's re-factor the log parsing script. It's much more testable and more maintainable if we separate out the parsing logic into its own file.
parser.js
// Parser constructor. var Parser = function() { }; // Parses the specified text. Parser.prototype.parse = function(text) { var results = {}; // Break up the file into lines. var lines = text.split('\n'); lines.forEach(function(line) { var parts = line.split(' '); var letter = parts[1]; var count = parseInt(parts[2]); if(!results[letter]) { results[letter] = 0; } results[letter] += parseInt(count); }); return results; }; // Export the Parser constructor from this module. module.exports = Parser;What I did was create a new file to hold the logic for parsing logs. This is just standard JavaScript and there are many ways to encapsulate this code. I chose to define a new JavaScript object because it's easy to unit test.
The important piece to this is the "module.exports" line. This tells Node what you're exporting from this file. In this case I'm exporting the constructor, so users can create instances of my Parser object. You can export whatever you want.
Now let's look at how to import this file and make use of my new Parser object.
my_parser.js
// Require my new parser.js file. var Parser = require('./parser'); // Load the fs (filesystem) module. var fs = require('fs'); // Read the contents of the file into memory. fs.readFile('example_log.txt', function (err, logData) { // If an error occurred, throwing it will // display the exception and kill our app. if (err) throw err; // logData is a Buffer, convert to string. var text = logData.toString(); // Create an instance of the Parser object. var parser = new Parser(); // Call the parse function. console.log(parser.parse(text)); // { A: 2, B: 14, C: 6 } });Files are included exactly like modules, except you provide a path instead of a name. The .js extension is implied so you can leave it off if you want.
Since I exported the constructor that is what will be returned from the require statement. I can now create instances of my Parser object and use it.
Summary
Hopefully this tutorial can bridge the gap between downloading Node.js and building your first widget. Node.js is an extremely powerful and flexible technology that can solve a wide variety of problems.
I want everyone to remember that Node.js is only bound by your imagination. The core libraries are very carefully designed to provide the puzzle pieces needed to build any picture. Combine those with the modules available in npm and it's amazing how quickly you can begin building very complex and compelling applications.
If you have any questions or comments, feel free to drop them below.

HTML is great for declaring static documents, but it falters when we try to use it for declaring dynamic views in web-applications. AngularJS lets you extend HTML vocabulary for your application. The resulting environment is extraordinarily expressive, readable, and quick to develop.
Other frameworks deal with HTML's shortcomings by either abstracting away HTML, CSS, and/or JavaScript or by providing an imperative way for manipulating the DOM. Neither of these address the root problem that HTML was not designed for dynamic views.
AngularJS is a toolset for building the framework most suited to your application development. It is fully extensible and works well with other libraries. Every feature can be modified or replaced to suit your unique development workflow and feature needs. Read on to find out how.
Watch as we build this app
Data Binding
Data-binding is an automatic way of updating the view whenever the model changes, as well as updating the model whenever the view changes. This is awesome because it eliminates DOM manipulation from the list of things you have to worry about.
Controller
Controllers are the behavior behind the DOM elements. AngularJS lets you express the behavior in a clean readable form without the usual boilerplate of updating the DOM, registering callbacks or watching model changes.
Plain JavaScript
Unlike other frameworks, there is no need to inherit from proprietary types in order to wrap the model in accessors methods. Angular models are plain old JavaScript objects. This makes your code easy to test, maintain, reuse, and again free from boilerplate.
Watch as we build this app
Deep Linking
A deep link reflects where the user is in the app, this is useful so users can bookmark and email links to locations within apps. Round trip apps get this automatically, but AJAX apps by their nature do not. AngularJS combines the benefits of deep link with desktop app-like behavior.
Form Validation
Client-side form validation is an important part of great user experience. AngularJS lets you declare the validation rules of the form without having to write JavaScript code. Write less code, go have beer sooner.
Server Communication
AngularJS provides built-in services on top of XHR as well as various other backends using third party libraries. Promises further simplify your code by handling asynchronous return of data. In this example, we use the AngularFire library to wire up a Firebase backend to a simple Angular app.
Directives
Directives is a unique and powerful feature available only in Angular. Directives let you invent new HTML syntax, specific to your application.
Reusable Components
We use directives to create reusable components. A component allows you to hide complex DOM structure, CSS, and behavior. This lets you focus either on what the application does or how the application looks separately.
Localization
An important part of serious apps is localization. Angular's locale aware filters and stemming directives give you building blocks to make your application available in all locales.
Embeddable
AngularJS works great with other technologies. Add as much or as little of AngularJS to an existing page as you like. Many other frameworks require full commitment. This page has multiple AngularJS applications embedded in it. Because AngularJS has no global state multiple apps can run on a single page without the use of iframe s. We encourage you to view-source and look around.
Injectable
The dependency injection in AngularJS allows you to declaratively describe how your application is wired. This means that your application needs no main() method which is usually an unmaintainable mess. Dependency injection is also a core to AngularJS. This means that any component which does not fit your needs can easily be replaced.
Testable
AngularJS was designed from ground up to be testable. It encourages behavior-view separation, comes pre-bundled with mocks, and takes full advantage of dependency injection. It also comes with end-to-end scenario runner which eliminates test flakiness by understanding the inner workings of AngularJS.
Backbone.js gives structure to web applications by providing models with key-value binding and custom events, collections with a rich API of enumerable functions, views with declarative event handling, and connects it all to your existing API over a RESTful JSON interface.
The project is hosted on GitHub, and the annotated source code is available, as well as an online test suite, an example application, a list of tutorials and a long list of real-world projects that use Backbone. Backbone is available for use under the MIT software license.
You can report bugs and discuss features on the GitHub issues page, on Freenode IRC in the#documentcloud channel, post questions to the Google Group, add pages to the wiki or send tweets to@documentcloud.
Backbone is an open-source component of DocumentCloud.
Downloads & Dependencies (Right-click, and use "Save As")
Backbone's only hard dependency is Underscore.js ( >= 1.5.0). For RESTful persistence, history support via Backbone.Router and DOM manipulation with Backbone.View, include , and for older Internet Explorer support.(Mimics of the Underscore and jQuery APIs, such as Lo-Dash andZepto, will also tend to work, with varying degrees of compatibility.)
Introduction
When working on a web application that involves a lot of JavaScript, one of the first things you learn is to stop tying your data to the DOM. It's all too easy to create JavaScript applications that end up as tangled piles of jQuery selectors and callbacks, all trying frantically to keep data in sync between the HTML UI, your JavaScript logic, and the database on your server. For rich client-side applications, a more structured approach is often helpful.
With Backbone, you represent your data as Models, which can be created, validated, destroyed, and saved to the server. Whenever a UI action causes an attribute of a model to change, the model triggers a"change" event; all the Views that display the model's state can be notified of the change, so that they are able to respond accordingly, re-rendering themselves with the new information. In a finished Backbone app, you don't have to write the glue code that looks into the DOM to find an element with a specific id, and update the HTML manually - when the model changes, the views simply update themselves.
Philosophically, Backbone is an attempt to discover the minimal set of data-structuring (models and collections) and user interface (views and URLs) primitives that are generally useful when building web applications with JavaScript. In an ecosystem where overarching, decides-everything-for-you frameworks are commonplace, and many libraries require your site to be reorganized to suit their look, feel, and default behavior - Backbone should continue to be a tool that gives you the freedom to design the full experience of your web application.
If you're new here, and aren't yet quite sure what Backbone is for, start by browsing the list of Backbone-based projects.
Many of the examples that follow are runnable. Click the play button to execute them.
Upgrading to 1.1
Backbone 1.1 should be a fairly painless upgrade from the 0.9.X series. If you're upgrading from an older version, be sure to check out the change log. In brief, a few of the larger breaking changes are:
- If you want to smartly update the contents of a Collection, adding new models, removing missing ones, and merging those already present, you now call set (previously named "update"), a similar operation to callingset on a Model. This is now the default when you callfetch on a collection. To get the old behavior, pass{reset: true}.
- If you have characters in your URL segments that require URL encoding, Backbone will now decode them for you (normalizing the behavior cross-browser) before your route handlers receive them as arguments.
- In 0.9.x, Backbone events gained two new methods:listenTo andstopListening, which make it easier to create Views that have all of their observers unbound when you want toremove the view.
- Model validation is now only enforced by default in save - not inset unless the {validate:true} option is passed. Model validation now fires an"invalid" event instead of"error".
- In 1.1, Backbone Views no longer have the options argument attached asthis.options automatically. Feel free to continue attaching it if you like.
- In 1.1, The Collection methods add, remove,set, push, and shift now return the model (or models) added or removed from the collection.
Backbone.Events
Events is a module that can be mixed in to any object, giving the object the ability to bind and trigger custom named events. Events do not have to be declared before they are bound, and may take passed arguments. For example:
var object = {};
_.extend(object, Backbone.Events);
object.on("alert", function(msg) {
alert("Triggered " + msg);
});
object.trigger("alert", "an event");
For example, to make a handy event dispatcher that can coordinate events among different areas of your application: var dispatcher = _.clone(Backbone.Events)
object.on(event, callback, [context])Alias: bind
Bind a callback function to an object. The callback will be invoked whenever the event is fired. If you have a large number of different events on a page, the convention is to use colons to namespace them:"poll:start", or "change:selection". The event string may also be a space-delimited list of several events...
book.on("change:title change:author", ...);
To supply a context value for this when the callback is invoked, pass the optional third argument: model.on('change', this.render, this)
Callbacks bound to the special "all" event will be triggered when any event occurs, and are passed the name of the event as the first argument. For example, to proxy all events from one object to another:
proxy.on("all", function(eventName) {
object.trigger(eventName);
});
All Backbone event methods also support an event map syntax, as an alternative to positional arguments:
book.on({
"change:title": titleView.update,
"change:author": authorPane.update,
"destroy": bookView.remove
});
object.off([event], [callback], [context])Alias: unbind
Remove a previously-bound callback function from an object. If no context is specified, all of the versions of the callback with different contexts will be removed. If no callback is specified, all callbacks for the event will be removed. If no event is specified, callbacks for all events will be removed.
// Removes just the `onChange` callback.
object.off("change", onChange);
// Removes all "change" callbacks.
object.off("change");
// Removes the `onChange` callback for all events.
object.off(null, onChange);
// Removes all callbacks for `context` for all events.
object.off(null, null, context);
// Removes all callbacks on `object`.
object.off();
Note that calling model.off(), for example, will indeed remove all events on the model - including events that Backbone uses for internal bookkeeping.
object.listenTo(other, event, callback)
Tell an object to listen to a particular event on an other object. The advantage of using this form, instead of other.on(event, callback, object), is that listenTo allows the object to keep track of the events, and they can be removed all at once later on. The callback will always be called with object as context.
view.listenTo(model, 'change', view.render);
object.stopListening([other], [event], [callback])
Tell an object to stop listening to events. Either call stopListening with no arguments to have the object remove all of its registered callbacks ... or be more precise by telling it to remove just the events it's listening to on a specific object, or a specific event, or just a specific callback.
view.stopListening(); view.stopListening(model);
Here's the complete list of built-in Backbone events, with arguments. You're also free to trigger your own events on Models, Collections and Views as you see fit. The Backbone object itself mixes in Events, and can be used to emit any global events that your application needs.
- "add" (model, collection, options) - when a model is added to a collection.
- "remove" (model, collection, options) - when a model is removed from a collection.
- "reset" (collection, options) - when the collection's entire contents have been replaced.
- "sort" (collection, options) - when the collection has been re-sorted.
- "change" (model, options) - when a model's attributes have changed.
- "change:[attribute]" (model, value, options) - when a specific attribute has been updated.
- "destroy" (model, collection, options) - when a model is destroyed.
- "request" (model, xhr, options) - when a model (or collection) has started a request to the server.
- "sync" (model, resp, options) - when a model (or collection) has been successfully synced with the server.
- "error" (model, xhr, options) - when a model's save call fails on the server.
- "invalid" (model, error, options) - when a model's validation fails on the client.
- "route:[name]" (params) - Fired by the router when a specific route is matched.
- "route" (route, params) - Fired by the router when any route has been matched.
- "route" (router, route, params) - Fired by history when any route has been matched.
- "all" - this special event fires for any triggered event, passing the event name as the first argument.
Generally speaking, when calling a function that emits an event ( model.set, collection.add, and so on...), if you'd like to prevent the event from being triggered, you may pass{silent: true} as an option. Note that this is rarely, perhaps even never, a good idea. Passing through a specific flag in the options for your event callback to look at, and choose to ignore, will usually work out better.
Backbone.Model
Models are the heart of any JavaScript application, containing the interactive data as well as a large part of the logic surrounding it: conversions, validations, computed properties, and access control. You extend Backbone.Model with your domain-specific methods, and Model provides a basic set of functionality for managing changes.
The following is a contrived example, but it demonstrates defining a model with a custom method, setting an attribute, and firing an event keyed to changes in that specific attribute. After running this code once, sidebar will be available in your browser's console, so you can play around with it.
var Sidebar = Backbone.Model.extend({
promptColor: function() {
var cssColor = prompt("Please enter a CSS color:");
this.set({color: cssColor});
}
});
window.sidebar = new Sidebar;
sidebar.on('change:color', function(model, color) {
$('#sidebar').css({background: color});
});
sidebar.set({color: 'white'});
sidebar.promptColor();
Backbone.Model.extend(properties, [classProperties])
To create a Model class of your own, you extend Backbone.Model and provide instance properties, as well as optional classProperties to be attached directly to the constructor function.
extend correctly sets up the prototype chain, so subclasses created with extend can be further extended and subclassed as far as you like.
var Note = Backbone.Model.extend({
initialize: function() { ... },
author: function() { ... },
coordinates: function() { ... },
allowedToEdit: function(account) {
return true;
}
});
var PrivateNote = Note.extend({
allowedToEdit: function(account) {
return account.owns(this);
}
});
var Note = Backbone.Model.extend({
set: function(attributes, options) {
Backbone.Model.prototype.set.apply(this, arguments);
...
}
});
new Model([attributes], [options])
When creating an instance of a model, you can pass in the initial values of the attributes, which will be set on the model. If you define an initialize function, it will be invoked when the model is created.
new Book({
title: "One Thousand and One Nights",
author: "Scheherazade"
});
In rare cases, if you're looking to get fancy, you may want to override constructor, which allows you to replace the actual constructor function for your model.
var Library = Backbone.Model.extend({
constructor: function() {
this.books = new Books();
Backbone.Model.apply(this, arguments);
},
parse: function(data, options) {
this.books.reset(data.books);
return data.library;
}
});
If you pass a {collection: ...} as the options, the model gains a collection property that will be used to indicate which collection the model belongs to, and is used to help compute the model's url. The model.collection property is normally created automatically when you first add a model to a collection. Note that the reverse is not true, as passing this option to the constructor will not automatically add the model to the collection. Useful, sometimes.
If {parse: true} is passed as an option, the attributes will first be converted by parse before being set on the model.
note.set({title: "March 20", content: "In his eyes she eclipses..."});
book.set("title", "A Scandal in Bohemia");
model.escape(attribute)
Similar to get, but returns the HTML-escaped version of a model's attribute. If you're interpolating data from the model into HTML, using escape to retrieve attributes will prevent XSS attacks.
var hacker = new Backbone.Model({
name: "<script>alert('xss')</script>"
});
alert(hacker.escape('name'));
if (note.has("title")) {
...
}
model.unset(attribute, [options])
Remove an attribute by deleting it from the internal attributes hash. Fires a"change" event unless silent is passed as an option.
var Meal = Backbone.Model.extend({
idAttribute: "_id"
});
var cake = new Meal({ _id: 1, name: "Cake" });
alert("Cake id: " + cake.id);
model.attributes
The attributes property is the internal hash containing the model's state - usually (but not necessarily) a form of the JSON object representing the model data on the server. It's often a straightforward serialization of a row from the database, but it could also be client-side computed state.
Please use set to update the attributes instead of modifying them directly. If you'd like to retrieve and munge a copy of the model's attributes, use_.clone(model.attributes) instead.
Due to the fact that Events accepts space separated lists of events, attribute names should not include spaces.
model.changed
The changed property is the internal hash containing all the attributes that have changed since the last set. Please do not update changed directly since its state is internally maintained by set. A copy of changed can be acquired from changedAttributes.
model.defaults or model.defaults()
The defaults hash (or function) can be used to specify the default attributes for your model. When creating an instance of the model, any unspecified attributes will be set to their default value.
var Meal = Backbone.Model.extend({
defaults: {
"appetizer": "caesar salad",
"entree": "ravioli",
"dessert": "cheesecake"
}
});
alert("Dessert will be " + (new Meal).get('dessert'));
Remember that in JavaScript, objects are passed by reference, so if you include an object as a default value, it will be shared among all instances. Instead, define defaults as a function.
model.toJSON([options])
Return a shallow copy of the model's attributes for JSON stringification. This can be used for persistence, serialization, or for augmentation before being sent to the server. The name of this method is a bit confusing, as it doesn't actually return a JSON string - but I'm afraid that it's the way that the JavaScript API for JSON.stringify works.
var artist = new Backbone.Model({
firstName: "Wassily",
lastName: "Kandinsky"
});
artist.set({birthday: "December 16, 1866"});
alert(JSON.stringify(artist));
model.fetch([options])
Resets the model's state from the server by delegating to Backbone.sync. Returns a jqXHR. Useful if the model has never been populated with data, or if you'd like to ensure that you have the latest server state. A"change" event will be triggered if the server's state differs from the current attributes. Accepts success and error callbacks in the options hash, which are both passed(model, response, options) as arguments.
// Poll every 10 seconds to keep the channel model up-to-date.
setInterval(function() {
channel.fetch();
}, 10000);
model.save([attributes], [options])
Save a model to your database (or alternative persistence layer), by delegating to Backbone.sync. Returns a jqXHR if validation is successful and false otherwise. The attributes hash (as in set) should contain the attributes you'd like to change - keys that aren't mentioned won't be altered - but, a complete representation of the resource will be sent to the server. As with set, you may pass individual keys and values instead of a hash. If the model has a validate method, and validation fails, the model will not be saved. If the model isNew, the save will be a "create" (HTTP POST), if the model already exists on the server, the save will be an"update" (HTTP PUT).
If instead, you'd only like the changed attributes to be sent to the server, call model.save(attrs, {patch: true}). You'll get an HTTP PATCH request to the server with just the passed-in attributes.
Calling save with new attributes will cause a "change" event immediately, a"request" event as the Ajax request begins to go to the server, and a"sync" event after the server has acknowledged the successful change. Pass{wait: true} if you'd like to wait for the server before setting the new attributes on the model.
Backbone.sync = function(method, model) {
alert(method + ": " + JSON.stringify(model));
model.id = 1;
};
var book = new Backbone.Model({
title: "The Rough Riders",
author: "Theodore Roosevelt"
});
book.save();
book.save({author: "Teddy"});
save accepts success and error callbacks in the options hash, which are passed(model, response, options) and(model, xhr, options) as arguments, respectively. If a server-side validation fails, return a non- 200 HTTP response code, along with an error response in text or JSON.
book.save("author", "F.D.R.", {error: function(){ ... }});
model.destroy([options])
Destroys the model on the server by delegating an HTTP DELETE request to Backbone.sync. Returns a jqXHR object, or false if the model isNew. Accepts success and error callbacks in the options hash, which are passed(model, response, options) and (model, xhr, options) as arguments, respectively. Triggers a"destroy" event on the model, which will bubble up through any collections that contain it, a"request" event as it begins the Ajax request to the server, and a"sync" event, after the server has successfully acknowledged the model's deletion. Pass{wait: true} if you'd like to wait for the server to respond before removing the model from the collection.
book.destroy({success: function(model, response) {
...
}});
Backbone proxies to Underscore.js to provide 6 object functions on Backbone.Model. They aren't all documented here, but you can take a look at the Underscore documentation for the full details...
user.pick('first_name', 'last_name', 'email');
chapters.keys().join(', ');
var Chapter = Backbone.Model.extend({
validate: function(attrs, options) {
if (attrs.end < attrs.start) {
return "can't end before it starts";
}
}
});
var one = new Chapter({
title : "Chapter One: The Beginning"
});
one.on("invalid", function(model, error) {
alert(model.get("title") + " " + error);
});
one.save({
start: 15,
end: 10
});
"invalid" events are useful for providing coarse-grained error messages at the model or collection level.
var Chapter = Backbone.Model.extend({
validate: function(attrs, options) {
if (attrs.end < attrs.start) {
return "can't end before it starts";
}
}
});
var one = new Chapter({
title : "Chapter One: The Beginning"
});
one.set({
start: 15,
end: 10
});
if (!one.isValid()) {
alert(one.get("title") + " " + one.validationError);
}
model.url()
Returns the relative URL where the model's resource would be located on the server. If your models are located somewhere else, override this method with the correct logic. Generates URLs of the form:"[collection.url]/[id]" by default, but you may override by specifying an explicit urlRoot if the model's collection shouldn't be taken into account.
Delegates to Collection#url to generate the URL, so make sure that you have it defined, or a urlRoot property, if all models of this class share a common root URL. A model with an id of 101, stored in a Backbone.Collection with a url of "/documents/7/notes", would have this URL:"/documents/7/notes/101"
model.urlRoot or model.urlRoot()
Specify a urlRoot if you're using a model outside of a collection, to enable the default url function to generate URLs based on the model id."[urlRoot]/id"
Normally, you won't need to define this. Note that urlRoot may also be a function.
var Book = Backbone.Model.extend({urlRoot : '/books'});
var solaris = new Book({id: "1083-lem-solaris"});
alert(solaris.url());
model.parse(response, options)
parse is called whenever a model's data is returned by the server, in fetch, and save. The function is passed the raw response object, and should return the attributes hash to be set on the model. The default implementation is a no-op, simply passing through the JSON response. Override this if you need to work with a preexisting API, or better namespace your responses.
If you're working with a Rails backend that has a version prior to 3.1, you'll notice that its default to_json implementation includes a model's attributes under a namespace. To disable this behavior for seamless Backbone integration, set:
ActiveRecord::Base.include_root_in_json = false
model.clone()
Returns a new instance of the model with identical attributes.
model.hasChanged([attribute])
Has the model changed since the last set? If an attribute is passed, returns true if that specific attribute has changed.
Note that this method, and the following change-related ones, are only useful during the course of a "change" event.
book.on("change", function() {
if (book.hasChanged("title")) {
...
}
});
model.changedAttributes([attributes])
Retrieve a hash of only the model's attributes that have changed since the last set, or false if there are none. Optionally, an external attributes hash can be passed in, returning the attributes in that hash which differ from the model. This can be used to figure out which portions of a view should be updated, or what calls need to be made to sync the changes to the server.
var bill = new Backbone.Model({
name: "Bill Smith"
});
bill.on("change:name", function(model, name) {
alert("Changed name from " + bill.previous("name") + " to " + name);
});
bill.set({name : "Bill Jones"});
model.previousAttributes()
Return a copy of the model's previous attributes. Useful for getting a diff between versions of a model, or getting back to a valid state after an error occurs.
Backbone.Collection
Collections are ordered sets of models. You can bind "change" events to be notified when any model in the collection has been modified, listen for"add" and "remove" events, fetch the collection from the server, and use a full suite of Underscore.js methods.
Any event that is triggered on a model in a collection will also be triggered on the collection directly, for convenience. This allows you to listen for changes to specific attributes in any model in a collection, for example: documents.on("change:selected", ...)
Backbone.Collection.extend(properties, [classProperties])
To create a Collection class of your own, extend Backbone.Collection, providing instance properties, as well as optional classProperties to be attached directly to the collection's constructor function.
collection.model
Override this property to specify the model class that the collection contains. If defined, you can pass raw attributes objects (and arrays) to add, create, and reset, and the attributes will be converted into a model of the proper type.
var Library = Backbone.Collection.extend({
model: Book
});
A collection can also contain polymorphic models by overriding this property with a constructor that returns a model.
var Library = Backbone.Collection.extend({
model: function(attrs, options) {
if (condition) {
return new PublicDocument(attrs, options);
} else {
return new PrivateDocument(attrs, options);
}
}
});
new Backbone.Collection([models], [options])
When creating a Collection, you may choose to pass in the initial array of models. The collection's comparator may be included as an option. Passing false as the comparator option will prevent sorting. If you define an initialize function, it will be invoked when the collection is created. There are a couple of options that, if provided, are attached to the collection directly: model and comparator.
var tabs = new TabSet([tab1, tab2, tab3]);
var spaces = new Backbone.Collection([], {
model: Space
});
collection.models
Raw access to the JavaScript array of models inside of the collection. Usually you'll want to use get, at, or the Underscore methods to access model objects, but occasionally a direct reference to the array is desired.
collection.toJSON([options])
Return an array containing the attributes hash of each model (via toJSON) in the collection. This can be used to serialize and persist the collection as a whole. The name of this method is a bit confusing, because it conforms to JavaScript's JSON API.
var collection = new Backbone.Collection([
{name: "Tim", age: 5},
{name: "Ida", age: 26},
{name: "Rob", age: 55}
]);
alert(JSON.stringify(collection));
Backbone proxies to Underscore.js to provide 28 iteration functions on Backbone.Collection. They aren't all documented here, but you can take a look at the Underscore documentation for the full details...
books.each(function(book) {
book.publish();
});
var titles = books.map(function(book) {
return book.get("title");
});
var publishedBooks = books.filter(function(book) {
return book.get("published") === true;
});
var alphabetical = books.sortBy(function(book) {
return book.author.get("name").toLowerCase();
});
collection.add(models, [options])
Add a model (or an array of models) to the collection, firing an"add" event. If a model property is defined, you may also pass raw attributes objects, and have them be vivified as instances of the model. Returns the added (or preexisting, if duplicate) models. Pass{at: index} to splice the model into the collection at the specified index. If you're adding models to the collection that are already in the collection, they'll be ignored, unless you pass{merge: true}, in which case their attributes will be merged into the corresponding models, firing any appropriate"change" events.
var ships = new Backbone.Collection;
ships.on("add", function(ship) {
alert("Ahoy " + ship.get("name") + "!");
});
ships.add([
{name: "Flying Dutchman"},
{name: "Black Pearl"}
]);
Note that adding the same model (a model with the same id) to a collection more than once
is a no-op.
collection.reset([models], [options])
Adding and removing models one at a time is all well and good, but sometimes you have so many models to change that you'd rather just update the collection in bulk. Use reset to replace a collection with a new list of models (or attribute hashes), triggering a single"reset" event at the end. Returns the newly-set models. For convenience, within a"reset" event, the list of any previous models is available as options.previousModels.
Here's an example using reset to bootstrap a collection during initial page load, in a Rails application:
<script> var accounts = new Backbone.Collection; accounts.reset(<%= @accounts.to_json %>); </script>
Calling collection.reset() without passing any models as arguments will empty the entire collection.
collection.set(models, [options])
The set method performs a "smart" update of the collection with the passed list of models. If a model in the list isn't yet in the collection it will be added; if the model is already in the collection its attributes will be merged; and if the collection contains any models that aren't present in the list, they'll be removed. All of the appropriate"add", "remove", and "change" events are fired as this happens. Returns the touched models in the collection. If you'd like to customize the behavior, you can disable it with options:{add: false}, {remove: false}, or {merge: false}.
var vanHalen = new Backbone.Collection([eddie, alex, stone, roth]); vanHalen.set([eddie, alex, stone, hagar]); // Fires a "remove" event for roth, and an "add" event for "hagar". // Updates any of stone, alex, and eddie's attributes that may have // changed over the years.
collection.get(id)
Get a model from a collection, specified by an id, a cid, or by passing in a model.
var book = library.get(110);
collection.at(index)
Get a model from a collection, specified by index. Useful if your collection is sorted, and if your collection isn't sorted, at will still retrieve models in insertion order.
collection.comparator
By default there is no comparator for a collection. If you define a comparator, it will be used to maintain the collection in sorted order. This means that as models are added, they are inserted at the correct index in collection.models. A comparator can be defined as a sortBy (pass a function that takes a single argument), as a sort (pass a comparator function that expects two arguments), or as a string indicating the attribute to sort by.
Note how even though all of the chapters in this example are added backwards, they come out in the proper order:
var Chapter = Backbone.Model;
var chapters = new Backbone.Collection;
chapters.comparator = 'page';
chapters.add(new Chapter({page: 9, title: "The End"}));
chapters.add(new Chapter({page: 5, title: "The Middle"}));
chapters.add(new Chapter({page: 1, title: "The Beginning"}));
alert(chapters.pluck('title'));
Collections with a comparator will not automatically re-sort if you later change model attributes, so you may wish to call sort after changing model attributes that would affect the order.
collection.sort([options])
Force a collection to re-sort itself. You don't need to call this under normal circumstances, as a collection with a comparator will sort itself whenever a model is added. To disable sorting when adding a model, pass{sort: false} to add. Calling sort triggers a"sort" event on the collection.
var stooges = new Backbone.Collection([
{name: "Curly"},
{name: "Larry"},
{name: "Moe"}
]);
var names = stooges.pluck("name");
alert(JSON.stringify(names));
collection.where(attributes)
Return an array of all the models in a collection that match the passed attributes. Useful for simple cases of filter.
var friends = new Backbone.Collection([
{name: "Athos", job: "Musketeer"},
{name: "Porthos", job: "Musketeer"},
{name: "Aramis", job: "Musketeer"},
{name: "d'Artagnan", job: "Guard"},
]);
var musketeers = friends.where({job: "Musketeer"});
alert(musketeers.length);
collection.findWhere(attributes)
Just like where, but directly returns only the first model in the collection that matches the passed attributes.
var Notes = Backbone.Collection.extend({
url: '/notes'
});
// Or, something more sophisticated:
var Notes = Backbone.Collection.extend({
url: function() {
return this.document.url() + '/notes';
}
});
collection.parse(response, options)
parse is called by Backbone whenever a collection's models are returned by the server, in fetch. The function is passed the raw response object, and should return the array of model attributes to be added to the collection. The default implementation is a no-op, simply passing through the JSON response. Override this if you need to work with a preexisting API, or better namespace your responses.
var Tweets = Backbone.Collection.extend({
// The Twitter Search API returns tweets under "results".
parse: function(response) {
return response.results;
}
});
collection.clone()
Returns a new instance of the collection with an identical list of models.
collection.fetch([options])
Fetch the default set of models for this collection from the server, setting them on the collection when they arrive. The options hash takes success and error callbacks which will both be passed(collection, response, options) as arguments. When the model data returns from the server, it uses set to (intelligently) merge the fetched models, unless you pass{reset: true}, in which case the collection will be (efficiently) reset. Delegates to Backbone.sync under the covers for custom persistence strategies and returns a jqXHR. The server handler for fetch requests should return a JSON array of models.
Backbone.sync = function(method, model) {
alert(method + ": " + model.url);
};
var accounts = new Backbone.Collection;
accounts.url = '/accounts';
accounts.fetch();
The behavior of fetch can be customized by using the available set options. For example, to fetch a collection, getting an"add" event for every new model, and a"change" event for every changed existing model, without removing anything: collection.fetch({remove: false})
jQuery.ajax options can also be passed directly as fetch options, so to fetch a specific page of a paginated collection: Documents.fetch({data: {page: 3}})
Note that fetch should not be used to populate collections on page load - all models needed at load time should already be bootstrapped in to place. fetch is intended for lazily-loading models for interfaces that are not needed immediately: for example, documents with collections of notes that may be toggled open and closed.
collection.create(attributes, [options])
Convenience to create a new instance of a model within a collection. Equivalent to instantiating a model with a hash of attributes, saving the model to the server, and adding the model to the set after being successfully created. Returns the new model. If client-side validation failed, the model will be unsaved, with validation errors. In order for this to work, you should set the model property of the collection. The create method can accept either an attributes hash or an existing, unsaved model object.
Creating a model will cause an immediate "add" event to be triggered on the collection, a"request" event as the new model is sent to the server, as well as a"sync" event, once the server has responded with the successful creation of the model. Pass{wait: true} if you'd like to wait for the server before adding the new model to the collection.
var Library = Backbone.Collection.extend({
model: Book
});
var nypl = new Library;
var othello = nypl.create({
title: "Othello",
author: "William Shakespeare"
});
Backbone.Router
Web applications often provide linkable, bookmarkable, shareable URLs for important locations in the app. Until recently, hash fragments (#page) were used to provide these permalinks, but with the arrival of the History API, it's now possible to use standard URLs (/page). Backbone.Router provides methods for routing client-side pages, and connecting them to actions and events. For browsers which don't yet support the History API, the Router handles graceful fallback and transparent translation to the fragment version of the URL.
During page load, after your application has finished creating all of its routers, be sure to call Backbone.history.start(), or Backbone.history.start({pushState: true}) to route the initial URL.
var Workspace = Backbone.Router.extend({
routes: {
"help": "help", // #help
"search/:query": "search", // #search/kiwis
"search/:query/p:page": "search" // #search/kiwis/p7
},
help: function() {
...
},
search: function(query, page) {
...
}
});
router.routes
The routes hash maps URLs with parameters to functions on your router (or just direct function definitions, if you prefer), similar to the View's events hash. Routes can contain parameter parts,:param, which match a single URL component between slashes; and splat parts*splat, which can match any number of URL components. Part of a route can be made optional by surrounding it in parentheses(/:optional).
For example, a route of "search/:query/p:page" will match a fragment of#search/obama/p2, passing "obama" and"2" to the action.
A route of "docs/:section(/:subsection)" will match#docs/faq and #docs/faq/installing, passing"faq" to the action in the first case, and passing "faq" and"installing" to the action in the second.
When the visitor presses the back button, or enters a URL, and a particular route is matched, the name of the action will be fired as an event, so that other objects can listen to the router, and be notified. In the following example, visiting#help/uploading will fire a route:help event from the router.
routes: {
"help/:page": "help",
"download/*path": "download",
"folder/:name": "openFolder",
"folder/:name-:mode": "openFolder"
}
router.on("route:help", function(page) {
...
});
new Router([options])
When creating a new router, you may pass its routes hash directly as an option, if you choose. All options will also be passed to your initialize function, if defined.
router.route(route, name, [callback])
Manually create a route for the router, The route argument may be a routing string or regular expression. Each matching capture from the route or regular expression will be passed as an argument to the callback. The name argument will be triggered as a"route:name" event whenever the route is matched. If the callback argument is omitted router[name] will be used instead. Routes added later may override previously declared routes.
initialize: function(options) {
// Matches #page/10, passing "10"
this.route("page/:number", "page", function(number){ ... });
// Matches /117-a/b/c/open, passing "117-a/b/c" to this.open
this.route(/^(.*?)\/open$/, "open");
},
open: function(id) { ... }
openPage: function(pageNumber) {
this.document.pages.at(pageNumber).open();
this.navigate("page/" + pageNumber);
}
# Or ...
app.navigate("help/troubleshooting", {trigger: true});
# Or ...
app.navigate("help/troubleshooting", {trigger: true, replace: true});
Backbone.history
History serves as a global router (per frame) to handle hashchange events or pushState, match the appropriate route, and trigger callbacks. You shouldn't ever have to create one of these yourself since Backbone.history already contains one.
pushState support exists on a purely opt-in basis in Backbone. Older browsers that don't support pushState will continue to use hash-based URL fragments, and if a hash URL is visited by a pushState-capable browser, it will be transparently upgraded to the true URL. Note that using real URLs requires your web server to be able to correctly render those pages, so back-end changes are required as well. For example, if you have a route of/documents/100, your web server must be able to serve that page, if the browser visits that URL directly. For full search-engine crawlability, it's best to have the server generate the complete HTML for the page ... but if it's a web application, just rendering the same content you would have for the root URL, and filling in the rest with Backbone Views and JavaScript works fine.
Backbone.history.start([options])
When all of your Routers have been created, and all of the routes are set up properly, call Backbone.history.start() to begin monitoring hashchange events, and dispatching routes. Subsequent calls to Backbone.history.start() will throw an error, and Backbone.History.started is a boolean value indicating whether it has already been called.
To indicate that you'd like to use HTML5 pushState support in your application, use Backbone.history.start({pushState: true}). If you'd like to use pushState, but have browsers that don't support it natively use full page refreshes instead, you can add{hashChange: false} to the options.
If your application is not being served from the root url / of your domain, be sure to tell History where the root really is, as an option: Backbone.history.start({pushState: true, root: "/public/search/"})
If the server has already rendered the entire page, and you don't want the initial route to trigger when starting History, pass silent: true.
Because hash-based history in Internet Explorer relies on an <iframe>, be sure to only call start() after the DOM is ready.
$(function(){
new WorkspaceRouter();
new HelpPaneRouter();
Backbone.history.start({pushState: true});
});
Backbone.sync
Backbone.sync is the function that Backbone calls every time it attempts to read or save a model to the server. By default, it uses jQuery.ajax to make a RESTful JSON request and returns a jqXHR. You can override it in order to use a different persistence strategy, such as WebSockets, XML transport, or Local Storage.
The method signature of Backbone.sync is sync(method, model, [options])
- model - the model to be saved (or collection to be read)
- options - success and error callbacks, and all other jQuery request options
With the default implementation, when Backbone.sync sends up a request to save a model, its attributes will be passed, serialized as JSON, and sent in the HTTP body with content-type application/json. When returning a JSON response, send down the attributes of the model that have been changed by the server, and need to be updated on the client. When responding to a"read" request from a collection ( Collection#fetch), send down an array of model attribute objects.
Whenever a model or collection begins a sync with the server, a"request" event is emitted. If the request completes successfully you'll get a"sync" event, and an "error" event if not.
The sync function may be overriden globally as Backbone.sync, or at a finer-grained level, by adding a sync function to a Backbone collection or to an individual model.
The default sync handler maps CRUD to REST like so:
As an example, a Rails handler responding to an "update" call from Backbone might look like this: (In real code, never use update_attributes blindly, and always whitelist the attributes you allow to be changed.)
def update account = Account.find params[:id] account.update_attributes params render :json => account end
One more tip for integrating Rails versions prior to 3.1 is to disable the default namespacing for to_json calls on models by setting ActiveRecord::Base.include_root_in_json = false
Backbone.ajax = function(request) { ... };
If you want to use a custom AJAX function, or your endpoint doesn't support the jQuery.ajax API and you need to tweak things, you can do so by setting Backbone.ajax.
Backbone.emulateHTTP = true
If you want to work with a legacy web server that doesn't support Backbone's default REST/HTTP approach, you may choose to turn on Backbone.emulateHTTP. Setting this option will fake PUT and DELETE requests with a HTTP POST, setting the X-HTTP-Method-Override header with the true method. If emulateJSON is also on, the true method will be passed as an additional_method parameter.
Backbone.emulateHTTP = true; model.save(); // POST to "/collection/id", with "_method=PUT" + header.
Backbone.emulateJSON = true
If you're working with a legacy web server that can't handle requests encoded as application/json, setting Backbone.emulateJSON = true; will cause the JSON to be serialized under a model parameter, and the request to be made with a application/x-www-form-urlencoded MIME type, as if from an HTML form.
Backbone.View
Backbone views are almost more convention than they are code - they don't determine anything about your HTML or CSS for you, and can be used with any JavaScript templating library. The general idea is to organize your interface into logical views, backed by models, each of which can be updated independently when the model changes, without having to redraw the page. Instead of digging into a JSON object, looking up an element in the DOM, and updating the HTML by hand, you can bind your view's render function to the model's "change" event - and now everywhere that model data is displayed in the UI, it is always immediately up to date.
Backbone.View.extend(properties, [classProperties])
Get started with views by creating a custom view class. You'll want to override the render function, specify your declarative events, and perhaps the tagName, className, or id of the View's root element.
var DocumentRow = Backbone.View.extend({
tagName: "li",
className: "document-row",
events: {
"click .icon": "open",
"click .button.edit": "openEditDialog",
"click .button.delete": "destroy"
},
initialize: function() {
this.listenTo(this.model, "change", this.render);
},
render: function() {
...
}
});
Properties like tagName, id, className, el, and events may also be defined as a function, if you want to wait to define them until runtime.
new View([options])
There are several special options that, if passed, will be attached directly to the view: model, collection, el, id, className, tagName, attributes and events. If the view defines an initialize function, it will be called when the view is first created. If you'd like to create a view that references an element already in the DOM, pass in the element as an option: new View({el: existingElement})
var doc = documents.first();
new DocumentRow({
model: doc,
id: "document-row-" + doc.id
});
view.el
All views have a DOM element at all times (the el property), whether they've already been inserted into the page or not. In this fashion, views can be rendered at any time, and inserted into the DOM all at once, in order to get high-performance UI rendering with as few reflows and repaints as possible. this.el is created from the view's tagName, className, id and attributes properties, if specified. If not, el is an empty div.
var ItemView = Backbone.View.extend({
tagName: 'li'
});
var BodyView = Backbone.View.extend({
el: 'body'
});
var item = new ItemView();
var body = new BodyView();
alert(item.el + ' ' + body.el);
view.$el
A cached jQuery object for the view's element. A handy reference instead of re-wrapping the DOM element all the time.
view.$el.show(); listView.$el.append(itemView.el);
view.setElement(element)
If you'd like to apply a Backbone view to a different DOM element, use setElement, which will also create the cached $el reference and move the view's delegated events from the old element to the new one.
view.$(selector)
If jQuery is included on the page, each view has a$ function that runs queries scoped within the view's element. If you use this scoped jQuery function, you don't have to use model ids as part of your query to pull out specific elements in a list, and can rely much more on HTML class attributes. It's equivalent to running: view.$el.find(selector)
ui.Chapter = Backbone.View.extend({
serialize : function() {
return {
title: this.$(".title").text(),
start: this.$(".start-page").text(),
end: this.$(".end-page").text()
};
}
});
view.template([data])
While templating for a view isn't a function provided directly by Backbone, it's often a nice convention to define a template function on your views. In this way, when rendering your view, you have convenient access to instance data. For example, using Underscore templates:
var LibraryView = Backbone.View.extend({
template: _.template(...)
});
view.render()
The default implementation of render is a no-op. Override this function with your code that renders the view template from model data, and updates this.el with the new HTML. A good convention is to return this at the end of render to enable chained calls.
var Bookmark = Backbone.View.extend({
template: _.template(...),
render: function() {
this.$el.html(this.template(this.model.attributes));
return this;
}
});
Backbone is agnostic with respect to your preferred method of HTML templating. Your render function could even munge together an HTML string, or use document.createElement to generate a DOM tree. However, we suggest choosing a nice JavaScript templating library. Mustache.js, Haml-js, and Eco are all fine alternatives. Because Underscore.js is already on the page,_.template is available, and is an excellent choice if you prefer simple interpolated-JavaScript style templates.
Whatever templating strategy you end up with, it's nice if you never have to put strings of HTML in your JavaScript. At DocumentCloud, we use Jammit in order to package up JavaScript templates stored in/app/views as part of our main core.js asset package.
view.remove()
Removes a view from the DOM, and calls stopListening to remove any bound events that the view has listenTo'd.
delegateEvents([events])
Uses jQuery's on function to provide declarative callbacks for DOM events within a view. If an events hash is not passed directly, uses this.events as the source. Events are written in the format{"event selector": "callback"}. The callback may be either the name of a method on the view, or a direct function body. Omitting the selector causes the event to be bound to the view's root element ( this.el). By default, delegateEvents is called within the View's constructor for you, so if you have a simple events hash, all of your DOM events will always already be connected, and you will never have to call this function yourself.
The events property may also be defined as a function that returns an events hash, to make it easier to programmatically define your events, as well as inherit them from parent views.
Using delegateEvents provides a number of advantages over manually using jQuery to bind events to child elements during render. All attached callbacks are bound to the view before being handed off to jQuery, so when the callbacks are invoked, this continues to refer to the view object. When delegateEvents is run again, perhaps with a different events hash, all callbacks are removed and delegated afresh - useful for views which need to behave differently when in different modes.
A view that displays a document in a search result might look something like this:
var DocumentView = Backbone.View.extend({
events: {
"dblclick" : "open",
"click .icon.doc" : "select",
"contextmenu .icon.doc" : "showMenu",
"click .show_notes" : "toggleNotes",
"click .title .lock" : "editAccessLevel",
"mouseover .title .date" : "showTooltip"
},
render: function() {
this.$el.html(this.template(this.model.attributes));
return this;
},
open: function() {
window.open(this.model.get("viewer_url"));
},
select: function() {
this.model.set({selected: true});
},
...
});
undelegateEvents()
Removes all of the view's delegated events. Useful if you want to disable or remove a view from the DOM temporarily.
Utility
var backbone = Backbone.noConflict();
Returns the Backbone object back to its original value. You can use the return value of Backbone.noConflict() to keep a local reference to Backbone. Useful for embedding Backbone on third-party websites, where you don't want to clobber the existing Backbone.
var localBackbone = Backbone.noConflict(); var model = localBackbone.Model.extend(...);
Examples
The list of examples that follows, while long, is not exhaustive. If you've worked on an app that uses Backbone, please add it to the wiki page of Backbone apps.
DocumentCloud
The DocumentCloud workspace is built on Backbone.js, with Documents, Projects, Notes, and Accounts all as Backbone models and collections. If you're interested in history - both Underscore.js and Backbone.js were originally extracted from the DocumentCloud codebase, and packaged into standalone JS libraries.
USA Today
USA Today takes advantage of the modularity of Backbone's data/model lifecycle - which makes it simple to create, inherit, isolate, and link application objects - to keep the codebase both manageable and efficient. The new website also makes heavy use of the Backbone Router to control the page for both pushState-capable and legacy browsers. Finally, the team took advantage of Backbone's Event module to create a PubSub API that allows third parties and analytics packages to hook into the heart of the app.
Rdio
New Rdio was developed from the ground up with a component based framework based on Backbone.js. Every component on the screen is dynamically loaded and rendered, with data provided by the Rdio API. When changes are pushed, every component can update itself without reloading the page or interrupting the user's music. All of this relies on Backbone's views and models, and all URL routing is handled by Backbone's Router. When data changes are signaled in realtime, Backbone's Events notify the interested components in the data changes. Backbone forms the core of the new, dynamic, realtime Rdio web and desktop applications.
Hulu
Hulu used Backbone.js to build its next generation online video experience. With Backbone as a foundation, the web interface was rewritten from scratch so that all page content can be loaded dynamically with smooth transitions as you navigate. Backbone makes it easy to move through the app quickly without the reloading of scripts and embedded videos, while also offering models and collections for additional data manipulation support.
Quartz
Quartz sees itself as a digitally native news outlet for the new global economy. Because Quartz believes in the future of open, cross-platform web applications, they selected Backbone and Underscore to fetch, sort, store, and display content from a custom WordPress API. Although qz.com uses responsive design for phone, tablet, and desktop browsers, it also takes advantage of Backbone events and views to render device-specific templates in some cases.
Gawker Media
Kinja is Gawker Media's publishing platform designed to create great stories by breaking down the lines between the traditional roles of content creators and consumers. Everyone - editors, readers, marketers - have access to the same tools to engage in passionate discussion and pursue the truth of the story. Sharing, recommending, and following within the Kinja ecosystem allows for improved information discovery across all the sites.
Kinja is the platform behind Gawker, Gizmodo, Lifehacker, io9 and other Gawker Media blogs. Backbone.js underlies the front-end application code that powers everything from user authentication to post authoring, commenting, and even serving ads. The JavaScript stack includes Underscore.js and jQuery, with some plugins, all loaded with RequireJS. Closure templates are shared between the Play! Framework based Scala application and Backbone views, and the responsive layout is done with the Foundation framework using SASS.
Flow
MetaLab used Backbone.js to create Flow, a task management app for teams. The workspace relies on Backbone.js to construct task views, activities, accounts, folders, projects, and tags. You can see the internals under window.Flow.
Gilt Groupe
NewsBlur
WordPress.com
Foursquare
Foursquare is a fun little startup that helps you meet up with friends, discover new places, and save money. Backbone Models are heavily used in the core JavaScript API layer and Views power many popular features like the homepage map and lists.
Bitbucket
Disqus chose Backbone.js to power the latest version of their commenting widget. Backbone's small footprint and easy extensibility made it the right choice for Disqus' distributed web application, which is hosted entirely inside an iframe and served on thousands of large web properties, including IGN, Wired, CNN, MLB, and more.
Delicious
Khan Academy
eLife Lens
eLife Lens is a novel system for writing on the web. Instead of tying the content to a presentation focused format, Lens treats content as data and makes the links that exist within a document easy to navigate. Backbone.js is used to structure the views, Substance Document for representing content and Ken for faceted filtering. Read more in the official introduction post or dig into the source code.
Do
IRCCloud
IRCCloud is an always-connected IRC client that you use in your browser - often leaving it open all day in a tab. The sleek web interface communicates with an Erlang backend via websockets and the IRCCloud API. It makes heavy use of Backbone.js events, models, views and routing to keep your IRC conversations flowing in real time.
Pitchfork
Spin
Spin pulls in the latest news stories from their internal API onto their site using Backbone models and collections, and a custom sync method. Because the music should never stop playing, even as you click through to different "pages", Spin uses a Backbone router for navigation within the site.
ZocDoc
Walmart Mobile
Groupon Now!
Groupon Now! helps you find local deals that you can buy and use right now. When first developing the product, the team decided it would be AJAX heavy with smooth transitions between sections instead of full refreshes, but still needed to be fully linkable and shareable. Despite never having used Backbone before, the learning curve was incredibly quick - a prototype was hacked out in an afternoon, and the team was able to ship the product in two weeks. Because the source is minimal and understandable, it was easy to add several Backbone extensions for Groupon Now!: changing the router to handle URLs with querystring parameters, and adding a simple in-memory store for caching repeated requests for the same data.
Basecamp
Slavery Footprint allows consumers to visualize how their consumption habits are connected to modern-day slavery and provides them with an opportunity to have a deeper conversation with the companies that manufacture the goods they purchased. Based in Oakland, California, the Slavery Footprint team works to engage individuals, groups, and businesses to build awareness for and create deployable action against forced labor, human trafficking, and modern-day slavery through online tools, as well as off-line community education and mobilization programs.
Stripe
Stripe provides an API for accepting credit cards on the web. Stripe's management interface was recently rewritten from scratch in CoffeeScript using Backbone.js as the primary framework, Eco for templates, Sass for stylesheets, and Stitch to package everything together as CommonJS modules. The new app uses Stripe's API directly for the majority of its actions; Backbone.js models made it simple to map client-side models to their corresponding RESTful resources.
Airbnb
SoundCloud Mobile
SoundCloud is the leading sound sharing platform on the internet, and Backbone.js provides the foundation for SoundCloud Mobile. The project uses the public SoundCloud API as a data source (channeled through a nginx proxy), jQuery templates for the rendering, Qunit and PhantomJS for the testing suite. The JS code, templates and CSS are built for the production deployment with various Node.js tools like ready.js, Jake, jsdom. The Backbone.History was modified to support the HTML5 history.pushState. Backbone.sync was extended with an additional SessionStorage based cache layer.
Art.sy
Pandora
When Pandora redesigned their site in HTML5, they chose Backbone.js to help manage the user interface and interactions. For example, there's a model that represents the "currently playing track", and multiple views that automatically update when the current track changes. The station list is a collection, so that when stations are added or changed, the UI stays up to date.
Inkling
Code School
CloudApp
SeatGeek
Easel
Easel is an in-browser, high fidelity web design tool that integrates with your design and development process. The Easel team uses CoffeeScript, Underscore.js and Backbone.js for their rich visual editor as well as other management functions throughout the site. The structure of Backbone allowed the team to break the complex problem of building a visual editor into manageable components and still move quickly.
Jolicloud
Syllabus
Salon.io
TileMill
Blossom
Trello
Trello is a collaboration tool that organizes your projects into boards. A Trello board holds many lists of cards, which can contain checklists, files and conversations, and may be voted on and organized with labels. Updates on the board happen in real time. The site was built ground up using Backbone.js for all the models, views, and routes.
Tzigla
Cristi Balan and Irina Dumitrascu created Tzigla, a collaborative drawing application where artists make tiles that connect to each other to create surreal drawings. Backbone models help organize the code, routers provide bookmarkable deep links, and the views are rendered with haml.js and Zepto. Tzigla is written in Ruby ( Rails) on the backend, and CoffeeScript on the frontend, with Jammit prepackaging the static assets.
F.A.Q.
If your eye hasn't already been caught by the adaptability and elan on display in the above list of examples, we can get more specific: Backbone.js aims to provide the common foundation that data-rich web applications with ambitious interfaces require - while very deliberately avoiding painting you into a corner by making any decisions that you're better equipped to make yourself.
- The focus is on supplying you with helpful methods to manipulate and query your data, not on HTML widgets or reinventing the JavaScript object model.
- Backbone does not force you to use a single template engine. Views can bind to HTML constructed in yourfavoriteway.
- It's smaller. There are fewer kilobytes for your browser or phone to download, and less conceptual surface area. You can read and understand the source in an afternoon.
- It doesn't depend on stuffing application logic into your HTML. There's no embedded JavaScript, template logic, or binding hookup code in data- or ng- attributes, and no need to invent your own HTML tags.
- Synchronous events are used as the fundamental building block, not a difficult-to-reason-about run loop, or by constantly polling and traversing your data structures to hunt for changes. And if you want a specific event to be asynchronous and aggregated,no problem.
- Backbone scales well, from embedded widgets tomassive apps.
- Backbone is a library, not a framework, and plays well with others. You can embed Backbone widgets in Dojo apps without trouble, or use Backbone models as the data backing for D3 visualizations (to pick two entirely random examples).
- "Two way data-binding" is avoided. While it certainly makes for a nifty demo, and works for the most basic CRUD, it doesn't tend to be terribly useful in your real-world app. Sometimes you want to update on every keypress, sometimes on blur, sometimes when the panel is closed, and sometimes when the "save" button is clicked. In almost all cases, simply serializing the form to JSON is faster and easier. All that aside, if your heart is set, gofor it.
- There's no built-in performance penalty for choosing to structure your code with Backbone. And if you do want to optimize further, thin models and templates with flexible granularity make it easy to squeeze every last drop of potential performance out of, say, IE8.
It's common for folks just getting started to treat the examples listed on this page as some sort of gospel truth. In fact, Backbone.js is intended to be fairly agnostic about many common patterns in client-side code. For example...
References between Models and Views can be handled several ways. Some people like to have direct pointers, where views correspond 1:1 with models ( model.view and view.model). Others prefer to have intermediate "controller" objects that orchestrate the creation and organization of views into a hierarchy. Others still prefer the evented approach, and always fire events instead of calling methods directly. All of these styles work well.
Batch operations on Models are common, but often best handled differently depending on your server-side setup. Some folks don't mind making individual Ajax requests. Others create explicit resources for RESTful batch operations:/notes/batch/destroy?ids=1,2,3,4. Others tunnel REST over JSON, with the creation of "changeset" requests:
{
"create": [array of models to create]
"update": [array of models to update]
"destroy": [array of model ids to destroy]
}
Feel free to define your own events. Backbone.Events is designed so that you can mix it in to any JavaScript object or prototype. Since you can use any string as an event, it's often handy to bind and trigger your own custom events: model.on("selected:true") or model.on("editing")
Render the UI as you see fit. Backbone is agnostic as to whether you use Underscore templates, Mustache.js, direct DOM manipulation, server-side rendered snippets of HTML, or jQuery UI in your render function. Sometimes you'll create a view for each model ... sometimes you'll have a view that renders thousands of models at once, in a tight loop. Both can be appropriate in the same app, depending on the quantity of data involved, and the complexity of the UI.
It's common to nest collections inside of models with Backbone. For example, consider a Mailbox model that contains many Message models. One nice pattern for handling this is have a this.messages collection for each mailbox, enabling the lazy-loading of messages, when the mailbox is first opened ... perhaps with MessageList views listening for"add" and "remove" events.
var Mailbox = Backbone.Model.extend({
initialize: function() {
this.messages = new Messages;
this.messages.url = '/mailbox/' + this.id + '/messages';
this.messages.on("reset", this.updateCounts);
},
...
});
var inbox = new Mailbox;
// And then, when the Inbox is opened:
inbox.messages.fetch({reset: true});
If you're looking for something more opinionated, there are a number of Backbone plugins that add sophisticated associations among models, available on the wiki.
Backbone doesn't include direct support for nested models and collections or "has many" associations because there are a number of good patterns for modeling structured data on the client side, and Backbone should provide the foundation for implementing any of them. You may want to...
- Mirror an SQL database's structure, or the structure of a NoSQL database.
- Use models with arrays of "foreign key" ids, and join to top level collections (a-la tables).
- For associations that are numerous, use a range of ids instead of an explicit list.
- Avoid ids, and use direct references, creating a partial object graph representing your data set.
- Lazily load joined models from the server, or lazily deserialize nested models from JSON documents.
When your app first loads, it's common to have a set of initial models that you know you're going to need, in order to render the page. Instead of firing an extra AJAX request to fetch them, a nicer pattern is to have their data already bootstrapped into the page. You can then use reset to populate your collections with the initial data. At DocumentCloud, in the ERB template for the workspace, we do something along these lines:
<script> var accounts = new Backbone.Collection; accounts.reset(<%= @accounts.to_json %>); var projects = new Backbone.Collection; projects.reset(<%= @projects.to_json(:collaborators => true) %>); </script>
You have to escape</ within the JSON string, to prevent javascript injection attacks.
Many JavaScript libraries are meant to be insular and self-enclosed, where you interact with them by calling their public API, but never peek inside at the guts. Backbone.js is not that kind of library.
Because it serves as a foundation for your application, you're meant to extend and enhance it in the ways you see fit - the entire source code is annotated to make this easier for you. You'll find that there's very little there apart from core functions, and most of those can be overriden or augmented should you find the need. If you catch yourself adding methods to Backbone.Model.prototype, or creating your own base subclass, don't worry - that's how things are supposed to work.
Different implementations of the Model-View-Controller pattern tend to disagree about the definition of a controller. If it helps any, in Backbone, the View class can also be thought of as a kind of controller, dispatching events that originate from the UI, with the HTML template serving as the true view. We call it a View because it represents a logical chunk of UI, responsible for the contents of a single DOM element.
Comparing the overall structure of Backbone to a server-side MVC framework like Rails, the pieces line up like so:
- Backbone.Model - Like a Rails model minus the class methods. Wraps a row of data in business logic.
- Backbone.Collection - A group of models on the client-side, with sorting/filtering/aggregation logic.
- Backbone.Router - Rails routes.rb + Rails controller actions. Maps URLs to functions.
- Backbone.View - A logical, re-usable piece of UI. Often, but not always, associated with a model.
- Client-side Templates - Rails .html.erb views, rendering a chunk of HTML.
Perhaps the single most common JavaScript "gotcha" is the fact that when you pass a function as a callback, its value for this is lost. With Backbone, when dealing with events and callbacks, you'll often find it useful to rely on_.bind and_.bindAll from Underscore.js.
When binding callbacks to Backbone events, you can choose to pass an optional third argument to specify the this that will be used when the callback is later invoked:
var MessageList = Backbone.View.extend({
initialize: function() {
var messages = this.collection;
messages.on("reset", this.render, this);
messages.on("add", this.addMessage, this);
messages.on("remove", this.removeMessage, this);
}
});
// Later, in the app...
Inbox.messages.add(newMessage);
Backbone.js was originally extracted from a Rails application; getting your client-side (Backbone) Models to sync correctly with your server-side (Rails) Models is painless, but there are still a few things to be aware of.
By default, Rails versions prior to 3.1 add an extra layer of wrapping around the JSON representation of models. You can disable this wrapping by setting:
ActiveRecord::Base.include_root_in_json = false
... in your configuration. Otherwise, override parse to pull model attributes out of the wrapper. Similarly, Backbone PUTs and POSTs direct JSON representations of models, where by default Rails expects namespaced attributes. You can have your controllers filter attributes directly from params, or you can override toJSON in Backbone to add the extra wrapping Rails expects.
Change Log
- Oct. 10, 2013 - Diff
- Made the return values of Collection's set, add,remove, and reset more useful. Instead of returningthis, they now return the changed (added, removed or updated) model or list of models.
- Backbone Views no longer automatically attach options passed to the constructor as this.options, but you can do it yourself if you prefer.
- All "invalid" events now pass consistent arguments. First the model in question, then the error object, then options.
- You are no longer permitted to change the id of your model duringparse. Use idAttribute instead.
- On the other hand, parse is now an excellent place to extract and vivify incoming nested JSON into associated submodels.
- Many tweaks, optimizations and bugfixes relating to Backbone 1.0, including URL overrides, mutation of options, bulk ordering, trailing slashes, edge-case listener leaks, nested model parsing...
- Renamed Collection's "update" to set, for parallelism with the similarmodel.set(), and contrast withreset. It's now the default updating mechanism after afetch. If you'd like to continue using "reset", pass{reset: true}.
- Your route handlers will now receive their URL parameters pre-decoded.
- Added listenToOnce as the analogue ofonce.
- Added the findWhere method to Collections, similar towhere.
- Added the keys, values, pairs, invert,pick, and omit Underscore.js methods to Backbone Models.
- The routes in a Router's route map may now be function literals, instead of references to methods, if you like.
- url and urlRoot properties may now be passed as options when instantiating a new Model.
- A "route" event is triggered on the router in addition to being fired onBackbone.history.
- View#make has been removed. You'll need to use $ directly to construct DOM elements now.
- Passing {silent:true} on change will no longer delay individual"change:attr" events, instead they are silenced entirely.
- The Model#change method has been removed, as delayed attribute changes as no longer available.
- Bug fix where an empty response from the server on save would not call the success function.
- parse now receives options as its second argument.
- Model validation now fires invalid event instead oferror.
- Added listenTo andstopListening to Events. They can be used as inversion-of-control flavors ofon and off, for convenient unbinding of all events an object is currently listening to.view.remove() automatically calls view.stopListening().
- When using add on a collection, passing {merge: true} will now cause duplicate models to have their attributes merged in to the existing models, instead of being ignored.
- Added update (which is also available as an option tofetch) for "smart" updating of sets of models.
- HTTP PATCH support in save by passing{patch: true}.
- The Backbone object now extends Events so that you can use it as a global event bus, if you like.
- Added a "request" event to Backbone.sync, which triggers whenever a request begins to be made to the server. The natural complement to the"sync" event.
- Router URLs now support optional parts via parentheses, without having to use a regex.
- Backbone events now support jQuery-style event maps obj.on({click: action}).
- While listening to a reset event, the list of previous models is now available inoptions.previousModels, for convenience.
- Validation now occurs even during "silent" changes. This change means that theisValid method has been removed. Failed validations also trigger an error, even if an error callback is specified in the options.
- Consolidated "sync" and "error" events withinBackbone.sync. They are now triggered regardless of the existence ofsuccess or error callbacks.
- Collections now also proxy Underscore method name aliases (collect, inject, foldl, foldr, head, tail, take, and so on...)
- Removed getByCid from Collections. collection.get now supports lookup by bothid and cid.
- After fetching a model or a collection, all defined parse functions will now be run. So fetching a collection and getting back new models could cause both the collection to parse the list, and then each model to be parsed in turn, if you have both functions defined.
- Bugfix for normalizing leading and trailing slashes in the Router definitions. Their presence (or absence) should not affect behavior.
- When declaring a View, options, el, tagName,id and className may now be defined as functions, if you want their values to be determined at runtime.
- Added a Backbone.ajax hook for more convenient overriding of the default use of$.ajax. If AJAX is too passé, set it to your preferred method for server communication.
- To set what library Backbone uses for DOM manipulation and Ajax calls, use Backbone.$ = ... instead of setDomLibrary.
- Removed the Backbone.wrapError helper method. Overridingsync should work better for those particular use cases.
- For semantic and cross browser reasons, routes will now ignore search parameters. Routes like search?query=...&page=3 should becomesearch/.../3.
- Model#set no longer accepts another model as an argument. This leads to subtle problems and is easily replaced withmodel.set(other.attributes).
- Instead of throwing an error when adding duplicate models to a collection, Backbone will now silently skip them instead.
- Added push,pop,unshift, andshift to collections.
- A model's changed hash is now exposed for easy reading of the changed attribute delta, since the model's last"change" event.
- Added where to collections for simple filtering.
- You can now use a single off call to remove all callbacks bound to a specific object.
- Bug fixes for nested individual change events, some of which may be "silent".
- Bug fixes for URL encoding in location.hash fragments.
- Bug fix for client-side validation in advance of a save call with{wait: true}.
- Updated / refreshed the example Todo List app.
- Reverted to 0.5.3-esque behavior for validating models. Silent changes no longer trigger validation (making it easier to work with forms). Added an isValid function that you can use to check if a model is currently in a valid state.
- If you have multiple versions of jQuery on the page, you can now tell Backbone which one to use with Backbone.setDomLibrary.
- Fixes regressions in 0.9.0 for routing with "root", saving with both "wait" and "validate", and the order of nested "change" events.
- Two new properties on views: $el - a cached jQuery (or Zepto) reference to the view's element, andsetElement, which should be used instead of manually setting a view'sel. It will both setview.el and view.$el correctly, as well as re-delegating events on the new DOM element.
- You can now bind and trigger multiple spaced-delimited events at once. For example: model.on("change:name change:age", ...)
- When you don't know the key in advance, you may now call model.set(key, value) as well as save.
- Multiple models with the same id are no longer allowed in a single collection.
- Added a "sync" event, which triggers whenever a model's state has been successfully synced with the server (create, save, destroy).
- bind and unbind have been renamed to on andoff for clarity, following jQuery's lead. The old names are also still supported.
- A Backbone collection's comparator function may now behave either like asortBy (pass a function that takes a single argument), or like asort (pass a comparator function that expects two arguments). The comparator function is also now bound by default to the collection - so you can refer tothis within it.
- A view's events hash may now also contain direct function values as well as the string names of existing view methods.
- Validation has gotten an overhaul - a model's validate function will now be run even for silent changes, and you can no longer create a model in an initially invalid state.
- Added shuffle and initial to collections, proxied from Underscore.
- Model#urlRoot may now be defined as a function as well as a value.
- View#attributes may now be defined as a function as well as a value.
- Calling fetch on a collection will now cause all fetched JSON to be run through the collection's model'sparse function, if one is defined.
- Added an undelegateEvents to views, allowing you to manually remove all configured event delegations.
- Although you shouldn't be writing your routes with them in any case - leading slashes (/) are now stripped from routes.
- Calling clone on a model now only passes the attributes for duplication, not a reference to the model itself.
- Calling clear on a model now removes the id attribute.
- August 9, 2011 - Diff - Docs
A View's events property may now be defined as a function, as well as an object literal, making it easier to programmatically define and inherit events. groupBy is now proxied from Underscore as a method on Collections. If the server has already rendered everything on page load, pass Backbone.history.start({silent: true}) to prevent the initial route from triggering. Bugfix for pushState with encoded URLs.
- July 26, 2011 - Diff - Docs
The bind function, can now take an optional third argument, to specify the this of the callback function. Multiple models with the same id are now allowed in a collection. Fixed a bug where calling.fetch(jQueryOptions) could cause an incorrect URL to be serialized. Fixed a brief extra route fire before redirect, when degrading from pushState.
- July 5, 2011 - Diff - Docs
Cleanups from the 0.5.0 release, to wit: improved transparent upgrades from hash-based URLs to pushState, and vice-versa. Fixed inconsistency with non-modified attributes being passed to Model#initialize. Reverted a 0.5.0 change that would strip leading hashbangs from routes. Added contains as an alias for includes.
- July 1, 2011 - Diff - Docs
A large number of tiny tweaks and micro bugfixes, best viewed by looking at the commit diff. HTML5 pushState support, enabled by opting-in with: Backbone.history.start({pushState: true}). Controller was renamed to Router, for clarity. Collection#refresh was renamed to Collection#reset to emphasize its ability to both reset the collection with new models, as well as empty out the collection when used with no parameters. saveLocation was replaced with navigate. RESTful persistence methods (save, fetch, etc.) now return the jQuery deferred object for further success/error chaining and general convenience. Improved XSS escaping for Model#escape. Added a urlRoot option to allow specifying RESTful urls without the use of a collection. An error is thrown if Backbone.history.start is called multiple times. Collection#create now validates before initializing the new model. view.el can now be a jQuery string lookup. Backbone Views can now also take an attributes parameter. Model#defaults can now be a function as well as a literal attributes object.
- Dec 1, 2010 - Diff - Docs
Backbone.js now supports Zepto, alongside jQuery, as a framework for DOM manipulation and Ajax support. Implemented Model#escape, to efficiently handle attributes intended for HTML interpolation. When trying to persist a model, failed requests will now trigger an"error" event. The ubiquitous options argument is now passed as the final argument to all"change" events.
- Nov 23, 2010 - Diff - Docs
Bugfix for IE7 + iframe-based "hashchange" events. sync may now be overridden on a per-model, or per-collection basis. Fixed recursion error when calling save with no changed attributes, within a"change" event.
- Nov 15, 2010 - Diff - Docs
All"add" and "remove" events are now sent through the model, so that views can listen for them without having to know about the collection. Added a remove method to Backbone.View. toJSON is no longer called at all for 'read' and 'delete' requests. Backbone routes are now able to load empty URL fragments.
- Nov 9, 2010 - Diff - Docs
Backbone now has Controllers and History, for doing client-side routing based on URL fragments. Added emulateHTTP to provide support for legacy servers that don't do PUT and DELETE. Added emulateJSON for servers that can't accept application/json encoded requests. Added Model#clear, which removes all attributes from a model. All Backbone classes may now be seamlessly inherited by CoffeeScript classes.
- Oct 25, 2010 - Diff - Docs
Instead of requiring server responses to be namespaced under a model key, now you can define your own parse method to convert responses into attributes for Models and Collections. The old handleEvents function is now named delegateEvents, and is automatically called as part of the View's constructor. Added a toJSON function to Collections. Added Underscore's chain to Collections.
- Oct 19, 2010 - Diff - Docs
Added a Model#fetch method for refreshing the attributes of single model from the server. An error callback may now be passed to set and save as an option, which will be invoked if validation fails, overriding the"error" event. You can now tell backbone to use the_method hack instead of HTTP methods by setting Backbone.emulateHTTP = true. Existing Model and Collection data is no longer sent up unnecessarily with GET and DELETE requests. Added a rake lint task. Backbone is now published as an NPM module.
- Oct 14, 2010 - Diff - Docs
Added a convention for initialize functions to be called upon instance construction, if defined. Documentation tweaks.











Cappuccino is a framework which makes it easy to create advanced web apps. With just a few lines of code you can have an app built with full undo and redo, truly amazing table views, drag and drop and every modern UI appearance and behaviour you might expect on the desktop.
When you program in Cappuccino, you don't need to concern yourself with the complexities of document-focused web technologies like HTML, CSS, or even the DOM. Cappuccino is focused on making apps and the unpleasantries of building complex cross browser applications are abstracted away for you.


 Objective-J Language
Objective-J Language
Objective-J is a powerful object-oriented language which compiles to run in the browser. Because Objective-J is a superset of JavaScript, it's easy to mix and match. Objective-J extends JavaScript with traditional inheritance and Smalltalk/Objective-C style dynamic dispatch.

 Stunning Controls
Stunning Controls
Cappuccino's AppKit ships with a huge number of controls, each polished far beyond what's expected on the web. You can quickly build complex apps without reinventing the wheel every time you need a scrollable, sortable, virtual, auto-saves-column-settings table view.
* Fish widget not actually included.

 Interface Builder
Interface Builder
If you have a Mac you can build your Cappuccino user interface in Xcode's Interface Builder, just like you would in Cocoa. Skip the tweak-coordinated-rebuild-test cycle and just place labels and buttons where you need them. The XcodeCapp utility will do the rest.

Latest Version: 0.9.7 (November 28, 2013)
Beyond the starter pack, Cappuccino comes with a number of tools to make it easy to create new applications. With or without the starter pack, you can install all of Cappuccino and accompanying tools with the following command:
curl https://raw.github.com/cappuccino/cappuccino/v0.9.7/bootstrap.sh >/tmp/cb.sh && bash /tmp/cb.sh
Your download includes a README file with a few quick tips on how to get started.
You'll also probably want to check out our tutorials section. The get started one is designed specifically for figuring out what to do the very first time you download Cappuccino.
Getting the Source
If you'd like the full source, you can check it out from our GitHub repository, or clone it with this command:
git clone git://github.com/cappuccino/cappuccino.git
Learn more about contributing.
Highlights



An interview with 280 North on Objective-J and Cappuccino
I can see the allure of Objective-J / Cappuccino for building desktop-like Web applications. It gives you a very high level abstraction over the browser. No more DOM. No more CSS layouts, which can be the bane of your existence for a complicated and dynamic layout.
Dion Almaer, Ajaxian
From the Blog
After nearly a year's worth of work we are truly excited to introduce Cappuccino 0.9.7, a major update to the Cappuccino framework featuring a massive number of new features.
Since Cappuccino is such a wide framework, ranging from a low foundations such as our Objective-J compiler, all the way up to the full featured, fully themable UI kit AppKit, it's incredibly hard to summarise all the changes. But here's our best stab at it:
Cup - The File Upload Framework
A common need for Cappuccino apps is the ability to upload files. Until now, the only native Cappuccino upload solution was DeepDropUpload by David Cann. While DeepDropUpload works, it hasn't been updated in two years, and it doesn't integrate directly with Interface Builder.


I wrote a README the other day for a project that I'm hoping other developers will look at and learn from, and as I was writing it, I realized that it was the sort of thing that might have intimidated the hell out of me a couple of years ago, what with its casual mentions of Node, npm, Homebrew, git, tests, and development and production builds.
Once upon a time, editing files, testing them locally (as best as we could, anyway), and then FTPing them to the server was the essential workflow of a front-end dev. We measured our mettle based on our ability to wrangle IE6 into submission or achieve pixel perfection across browsers. Many members of the community - myself included - lacked traditional programming experience. HTML, CSS, and JavaScript - usually in the form of jQuery - were self-taught skills.
Something has changed in the last couple of years. Maybe it's the result of people starting to take front-end dev seriously, maybe it's browser vendors mostly getting their shit together, or maybe it's front-end devs - again, myself included - coming to see some well-established light about the process of software development.
Whatever it is, I think we're seeing the emphasis shift from valuing trivia to valuing tools. There's a new set of baseline skills required in order to be successful as a front-end developer, and developers who don't meet this baseline are going to start feeling more and more left behind as those who are sharing their knowledge start to assume that certain things go without saying.
Here are a few things that I want to start expecting people to be familiar with, along with some resources you can use if you feel like you need to get up to speed. (Thanks to Paul Irish, Mike Taylor, Angus Croll, and Vlad Filippov for their contributions.)
JavaScript
This might go without saying, but simply knowing a JavaScript library isn't sufficient any more. I'm not saying you need to know how to implement all the features of a library in plain JavaScript, but you should know when a library is actually required, and be capable of working with plain old JavaScript when it's not.
That means that you've read JavaScript: The Good Parts - hopefully more than once. You understand data structures like objects and arrays; functions, including how and why you would call and apply them; working with prototypal inheritance; and managing the asynchronicity of it all.
If your plain JS fu is weak, here are some resources to help you out:
Git (and a Github account)
If you're not on Github, you're essentially unable to participate in the rich open-source community that has arisen around front-end development technologies. Cloning a repo to try it out should be second-nature to you, and you should understand how to use branches on collaborative projects.
Need to boost your git skills?
Modularity, dependency management, and production builds
The days of managing dependencies by throwing one more script or style tag on the page are long gone. Even if you haven't been able to incorporate great tools like RequireJS into your workflow at work, you should find time to investigate them in a personal project or in a project like Backbone Boilerplate, because the benefits they convey are huge. RequireJS in particular lets you develop with small, modular JS and CSS files, and then concatenates and minifies them via its optimization tool for production use.
Skeptical of AMD? That's no excuse to be doing nothing. At the very least, you should be aware of tools like UglifyJS or Closure Compiler that will intelligently minify your code, and then concatenate those minified files prior to production.
If you're writing plain CSS - that is, if you're not using a preprocessor like Sass or Stylus - RequireJS can help you keep your CSS files modular, too. Use @import statements in a base file to load dependencies for development, and then run the RequireJS optimizer on the base file to create a file built for production.
In-Browser Developer Tools
Browser-based development tools have improved tremendously over the last couple of years, and they can dramatically improve your development experience if you know how to use them. (Hint: if you're still using alert to debug your code, you're wasting a lot of time.)
You should probably find one browser whose developer tools you primarily use - I'm partial to Google Chrome's Developer Tools these days - but don't dismiss the tools in other browsers out of hand, because they are constantly adding useful features based on developer feedback. Opera's Dragonfly in particular has some features that make its developer tools stand out, such as an (experimental) CSS profiler, customizable keyboard shortcuts, remote debugging without requiring a USB connection, and the ability to save and use custom color palettes.
If your understanding of browser dev tools is limited, Fixing these jQuery is a great (and not particularly jQuery-centric) overview of debugging, including how to do step debugging - a life-altering thing to learn if you don't already know it.
The command line
Speaking of the command line, being comfortable with it is no longer optional - you're missing out on way too much if you're not ready to head over to a terminal window and get your hands dirty. I'm not saying you have to do everything in the terminal - I won't take your git GUI away from you even though I think you'll be better off without it eventually - but you should absolutely have a terminal window open for whatever project you're working on. There are a few command line tasks you should be able to do without thinking:
-
sshto log in to another machine or server -
scpto copy files to another machine or server -
ackorgrepto find files in a project that contain a string or pattern -
findto locate files whose names match a given pattern -
gitto do at least basic things likeadd,commit,status, andpull -
brewto use Homebrew to install packages -
npmto install Node packages -
gemto install Ruby packages
If there are commands you use frequently, edit your .bashrc or .profile or .zshrc or whatever, and create an alias so you don't have to type as much. You can also add aliases to your ~/.gitconfig file. Gianni Chiappetta's dotfiles are an excellent inspiration for what's possible.
Client-side templating
It wasn't so long ago that it was entirely typical for servers to respond to XHRs with a snippet of HTML, but sometime in the last 12 to 18 months, the front-end dev community saw the light and started demanding pure data from the server instead. Turning that data into HTML ready to be inserted in the DOM can be a messy and unmaintainable process if it's done directly in your code. That's where client-side templating libraries come in: they let you maintain templates that, when mixed with some data, turn into a string of HTML. Need help picking a templating tool? Garann Means' template chooser can point you in the right direction.
CSS preprocessors
Paul Irish noted the other day that we're starting to see front-end devs write code that's very different from what ends up in production, and code written with CSS preprocessors is a shining example of this. There's still a vocal crowd that feels that pure CSS is the only way to go, but they're starting to come around. These tools give you features that arguably should be in CSS proper by now - variables, math, logic, mixins - and they can also help smooth over the CSS property prefix mess.
Testing
One of the joys of writing modular, loosely coupled code is that your code becomes vastly easier to test, and with tools like Grunt, setting up a project to include tests has never been easier. Grunt comes with QUnit integration, but there are a host of testing frameworks that you can choose from - Jasmine and Mocha are a couple of my current favorites - depending on your preferred style and the makeup of the rest of your stack.
While testing is a joy when your code is modular and loosely coupled, testing code that's not well organized can be somewhere between difficult and impossible. On the other hand, forcing yourself to write tests - perhaps before you even write the code - will help you organize your thinking and your code. It will also let you refactor your code with greater confidence down the line.
- A short screencast I recorded about testing your jQuery with Jasmine.
- An example of unit tests on the jquery-bbq plugin.
Process automation (rake/make/grunt/etc.)
Grunt's ability to set up a project with built-in support for unit tests is one example of process automation. The reality of front-end development is that there's a whole lot of repetitive stuff we have to do, but as a friend once told me, a good developer is a lazy developer: as a rule of thumb, if you find yourself doing the same thing three times, it's time to automate it.
Tools like make have been around for a long time to help us with this, but there's also rake, grunt, and others. Learning a language other than JavaScript can be extremely helpful if you want to automate tasks that deal with the filesystem, as Node's async nature can become a real burden when you're just manipulating files. There are lots of task-specific automation tools, too - tools for deployment, build generation, code quality assurance, and more.
Code quality
If you've ever been bitten by a missing semicolon or an extra comma, you know how much time can be lost to subtle flaws in your code. That's why you're running your code through a tool like JSHint, right? It's configurable and has lots of ways to integrate it into your editor or build process.
The fine manual
Alas, there is no manual for front-end development, but MDN comes pretty close. Good front-end devs know to prefix any search engine query with mdn - for example, mdn javascript arrays - in order to avoid the for-profit plague that is w3schools.
The End
As with anything, reading about these things won't make you an expert, or even moderately skilled - the only surefire way to get better at a thing is to do that thing. Good luck.


21 November 2013 | 10:15 am by Honza
Firebug team released Firebug 1.12.5. This version improves a workaround that solves Firefox tab switching and Firebug activation problem (due to a platform bug). See the detailed description of related changes below.
Firebug 1.12.5b1 has also been released to update users on AMO beta channel. This version is exactly the same as 1.12.5Firebug 1.12.5 is compatible with Firefox 23 - 26
Firebug 1.12.5 fixes 2 issues.
Script Panel Activation
Since version 1.12.4, Firebug doesn't pause the underlying Firefox JavaScript debugger engine (JSD) when the user is switching Firefox tabs. This avoids long tab switching times since JSD.pause/unPause is broken (it's the platform bug). This means that Firebug with active Script panel can slow down the browser even if it's on a background Firefox tab.
The user can see related warning message on disabled Script panel and also (if the Script panel is already enabled) within the Console panel.

 Enabling the Script panel causes a Firefox slow-down due to a platform bug. This will be fixed with the next major Firefox and Firebug versions.
Enabling the Script panel causes a Firefox slow-down due to a platform bug. This will be fixed with the next major Firefox and Firebug versions.If you have the Script panel disabled, the platform bug doesn't affect your browser experience.
Start Button Icon
In order to make it easier for the user to see that there is an active Firebug instance in the background we introduced a new state for the Start Button Icon (read more about the Start button).

Firebug is active on the current tab.

Firebug is not active on the current tab.

Firebug is active on a background tab (this is the new state).
Start Button Tooltip
Start button tooltip has also been improved. You can use it to see how many Firebug instances are currently active (you'll see the number even if Firebug is not active on the current tab).

The Screenshot shows that there are 3 active Firebugs in the browser (and the icon indicates that one of them is on the current page).
Shutdown Firebug
Finally, in order to quickly shutdown all Firebug instances at once and ensure that the underlying Firefox debugging engine (JSD) is deactivated (not slowing down the browser anymore), you can pick Clear Activation List from the Start button context menu.
Please post feedback in the newsgroup, thanks.
Jan 'Honza' Odvarko


